All in One View
Content from What is Wikidata?
Last updated on 2026-04-17 | Edit this page
Estimated time: 20 minutes
Overview
Questions
- What is Wikidata?
- How does the Wikidata interface look?
- How is Wikidata linked to other Wiki projects?
- What are Items and Statements?
Objectives
- Feel comfortable describing Wikidata to colleagues.
- Learn about Wikimedia projects (e.g. Wikipedia, WikiCommons) and how Wikidata is related to them.
- Know why linked open data is important to librarians.
- Be able to identify components of a Wikidata item page, how Wikidata is organized and how to navigate a Wikidata item.
What is Wikidata?
Wikidata describes itself as “a free and open knowledge base that can be read and edited by both humans and machines.”
Most users will be familiar with Wikipedia, the “free encyclopedia, written collaboratively by the people who use it. It is a special type of website designed to make collaboration easy, called a wiki. Many people are constantly improving Wikipedia, making thousands of changes per hour. All of these changes are recorded in article histories and recent changes.”
As librarian and developer Dan Scott has noted, rather than investing resources into enhancing local data silos like library catalogues or digital exhibits, libraries and archives can maximize the visibility and reusability of their data by enriching Wikidata as a centralized, open repository — and then pulling that data back into local systems.
Another sign of Wikidata’s growing importance: Google closed their own knowledge base project Freebase in 2016 in favor of backing Wikidata, and Google’s Knowledge Graph now draws on Wikidata data.
Wikidata uses the same speed and similar collaborative editing platform, but for data. Wikidata functions as the central database for a variety of Wiki projects, including Wikipedia, Wiktionary, and Wikisource, among others.
Wikidata contains various data types (e.g. text, images, quantities, coordinates, geographic shapes, dates). The data can be viewed in a web browser, but it can also be queried via a query interface called SPARQL, which we will cover later in this lesson. Data on Wikidata is published under the Creative Commons Public Domain 1.0 license. Thus, the data can be modified, copied, and distributed without permission.
Wikidata also contains authority files, bibliographic data, and other content that can similarly be found or managed in library databases.
Importantly, Wikidata can be understood as linked open data, which can be connected to other open data sets on the web.
Motivation and “Why should I use Wikidata”
Wikidata has many features that make it of interest to librarians and knowledge management, including:
Knowledge Integration and Access: Wikidata offers an open and structured way to interlink various identifiers (like ORCID, GND, or VIAF). This is essential for librarians who manage resources and need to ensure that different systems and databases can communicate with each other seamlessly.
Authority Control: Librarians often work with authority files like GND or VIAF to ensure consistent naming conventions. Wikidata helps to map and retrieve these identifiers, making cataloging more efficient.
Global and Collaborative Nature: Wikidata is a collaborative platform where librarians can contribute and maintain data, ensuring that their records stay relevant and up to date within a global information network.
Real-World Examples:
- Scholia: A tool built on top of Wikidata that visualizes scholarly profiles and research outputs, showing the impact of Wikidata in academic and research contexts. Librarians can showcase Scholia as a tangible example of how data in Wikidata is used for research and scholarship.
- Crosswalks between systems: Wikidata’s ability to link various identifiers (e.g., connecting ORCID to GND or VIAF) is beneficial for cross-referencing and data cleaning in library management systems.
1.1 Wikidata interface
This section of the lesson introduces the Wikidata interface as it can be seen in a web browser. Let’s learn about some of the important elements of how you can read and interact with the data on Wikidata.
-
Start by going to the Wikidata Main Page by typing “www.wikidata.org” into your browser. You will see something like this:
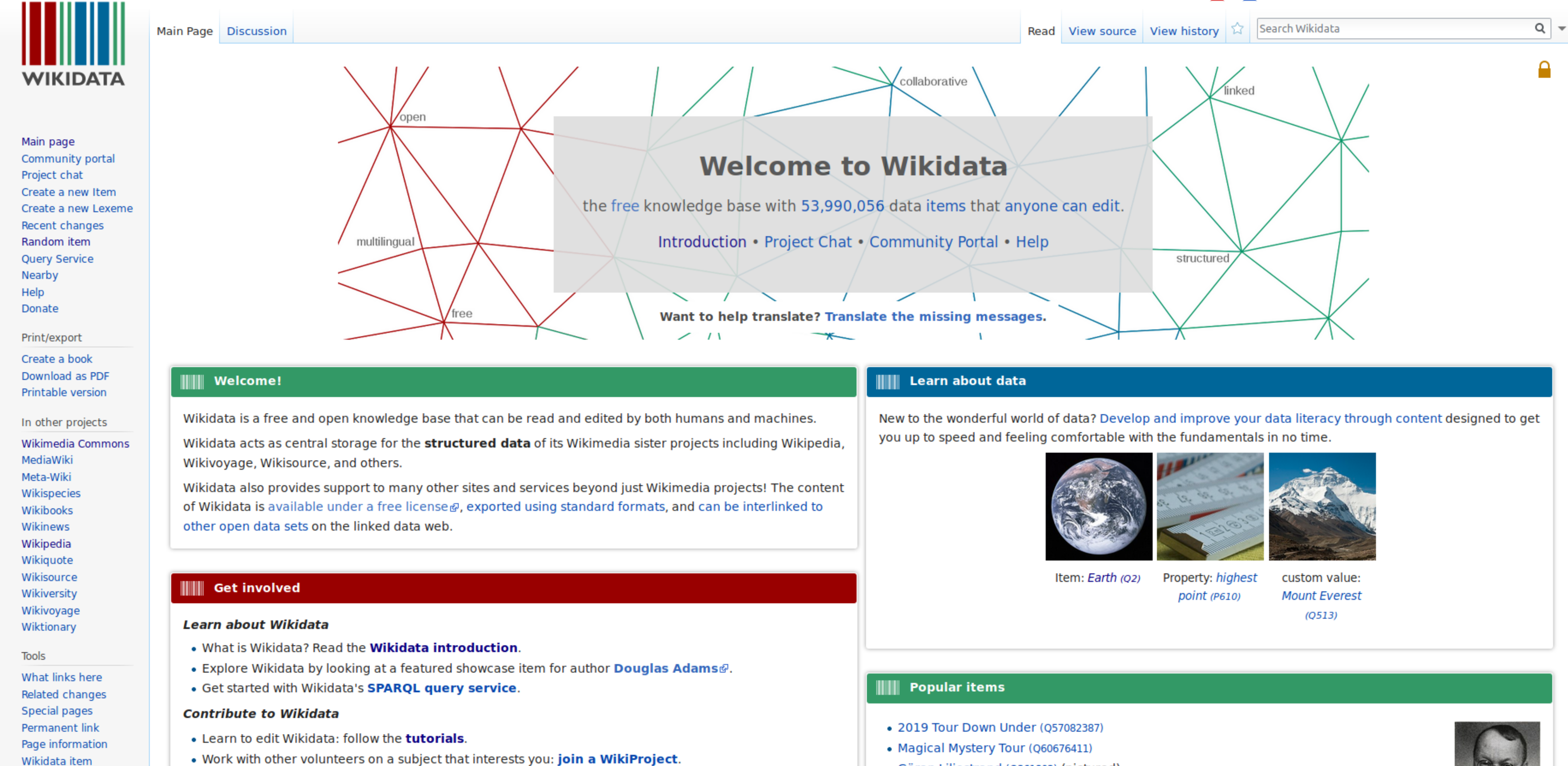
Screenshot of Wikidata Main Page
Explore Wikidata
Take 5 minutes to freely explore Wikidata. You could:
- Open a random item and see what you find
- Search for your hometown, a person you know, or your institution
- Look at how items are connected to each other
Share what you found with the group.
If you want a more structured activity, here are two options that work well as an introduction:
Note that these activities involve editing, so they may be better suited for later in the lesson once learners are more familiar with Wikidata.
There are also some Wikidata-specific games and tools that can be used as ice-breakers, but availability may vary — test them before the lesson:
1.2 Wikidata Items and Item Pages
The primary unit of data described on Wikidata are “items.” Each item
has an item page with a unique identifier designated by the letter
Q followed by a string of numbers. Let’s explore a Wikidata
item page, which will also demonstrate the characteristics of items in
Wikidata.
Explore a Wikidata Item page
Click in the search bar in the top right corner of the main page and enter “british library”. As you start typing, you will see a list with search results. Click the entry that says: “British Library (Q23308) national library of the United Kingdom”. Now you should see the british library’s item page: https://www.wikidata.org/wiki/Q23308
-
Let us explore the item British Library (Q23308). The top part of the item page identifies the item. Here you will see:
- label
- description
- unique identifier (constructed as the capital letter followed by one or more numbers)
- aliases
-
Farther down on the page is a Statements subheading. This section shows relationships, or claims, that have been asserted about the item. Statement may include:
- property (constructed as the capital letter P followed by one or more numbers)
- value
- qualifier (optional)
- references (optional)
- As you can see, a property can have multiple values. For example, member of indicates multiple values. These values can be further specified or supported by qualifiers (not shown on the item page for British Library)
- statements can also be called “triples,” since they include three parts (the item, the property relationship, and the property’s value), which we will look into more closely later on.
Wikidata items, as you can see above, have many special parts, like statements, qualifiers, and so on. The following diagram uses a different Wikidata item — Douglas Adams (Q42) — to illustrate the various elements of a Wikidata item and shows how they may appear on an item page. This is the official Wikidata example item and is widely used in Wikidata documentation:
){kind=link}

Wikidata editing and change history
Most pages can be edited by anyone (note, however, that the British Library - Q23308 item is semi-protected), and like other wiki projects, Wikidata tracks all changes made to an item. To see the changes made to an item, click “View history”. To edit an item, click the pen icon followed by the word “edit” in the upper-right area of an item page. Don’t worry if you made a mistake, you can always go back in an item’s history and restore or undo changes. We will explore the steps of editing a Wikidata item in episode 3, “Introduction to editing”.
1.3 Wikidata’s commitment to open data
All of Wikidata’s data is published freely and openly online under a Creative Commons CC0 License, which states: “The person who associated a work with this deed has dedicated the work to the public domain by waiving all of his or her rights to the work worldwide under copyright law, including all related and neighboring rights, to the extent allowed by law. You can copy, modify, distribute and perform the work, even for commercial purposes, all without asking permission.” In other words, the data is openly licensed and reusable. Since Wikidata can also be linked to other data sources on the web, this means Wikidata is linked open data.
- Follow this link to view a pdf that offers a one-page overview of Wikidata (visual): https://commons.wikimedia.org/wiki/File:Wikidata-in-brief-1.0.pdf
Explore a Wikidata Item
Locate the Wikidata page of the city or country you were born in. Look for the population.
- Has the population changed over time? Some wikidata pages appear in multiple languages.
- Are the aliases and data similar between Wikidata and the various Wikipedia entries in different languages?
- Compare the information in Wikipedia and Wikidata
- Depending on the detail and amount of information about a place, there may be multiple values regarding a city’s population. Because a city or country changes over time, Wikidata statements can be qualified, including with the addition of a start/end date, or by providing a citation for the data. The change in population over time provides a good example of the importance of providing qualifications for Wikidata staements.
1.4 Wikidata Item Eastereggs
While most of the Q identifiers are arbitrary numbers, there are a few that suggest some meaning or humor, such as:
1.5 Linking Wikidata to other Wiki resources
One of the most important and powerful aspects of Wikidata item pages is the final subheading, Identifiers. This is a special section that appears at the end of a Wikidata item page, and it is where information about how an item is identified in other databases or knowledge bases. Here, for example, is where you will find information about how an author’s Wikidata page relates to various national library catalogs, the Virtual International Authority File, or fan databases that document an author’s writings. This linking feature, which is quite highly developed in Wikipedia, makes the data especially valuable to libraries, archives, and other cultural heritage information.
As well as linking to external identifiers and authority sources, this section also has information about links to an item’s Wikipedia page (if there is one), as well as other WikiMedia projects, including WikiCommons, WikiSource, and others.
Links from Wikipedia to Wikidata
Let’s take a look at the relationships between Wikipedia and Wikidata. For example, how about Darwin’s On the Origin of Species, a notable scientific work that is discussed in both resources.
- What information is common between both resources? How would you describe the information in Wikidata, in comparison to that in Wikipedia? How are they similar or different?
- => Follow the link “Wikidata item” on the left side under “tools”
- => https://www.wikidata.org/wiki/Q20124
- => the Wikipedia article is linked on the Wikidata’s item page. You can find it on the right side.
- => link to WikiCommons and WikiSource
It is important to note that Wikidata is limited to basic statements or assertions, such as when the work was published, who and where it was published, and who wrote the work. This is similar to a catalog record. The Wikipedia article, on the other hand, discusses the themes and structure, the impact and reception of the work, and subsequent or ongoing debates.
- Wikidata entities are known as Items, and each item is displayed on a page that is identified with the item’s “Q” number
- Statements are assertions about items, which state relationships between items using wikidata properties.
- Relationships between entities are known as Properties, and each property is identified with a “P” number
- Statements are also known as “triples”
- Wikidata and Wikipedia are complementary, but Wikidata is focused on basic claims or assertions, not descriptive or narrative information
Content from Underlying concepts of Wikidata
Last updated on 2026-04-17 | Edit this page
Estimated time: 20 minutes
Overview
Questions
- What is a RDF triple?
- What are the underlying components of RDF?
- What tools and services are built on top of Wikidata?
Objectives
- Know what a triple is, and relate structure of a Wikidata statement to traditional metadata field structure.
- Know how linked data can create more context for patrons/users in library catalogs.
- Know how linked data can improve recall in library catalogs.
- Be aware of tools and services built on top of Wikidata, such as Scholia and InteractOA.
2.1 Conceptual foundations: ways of storing data
There are many types of database structures and systems. Two common database types are relational databases and graph databases. Understanding the commonalities and differencews between these structures helps to explain the uniqueness of Wikidata’s data structure.
2.1.1 Relational databases
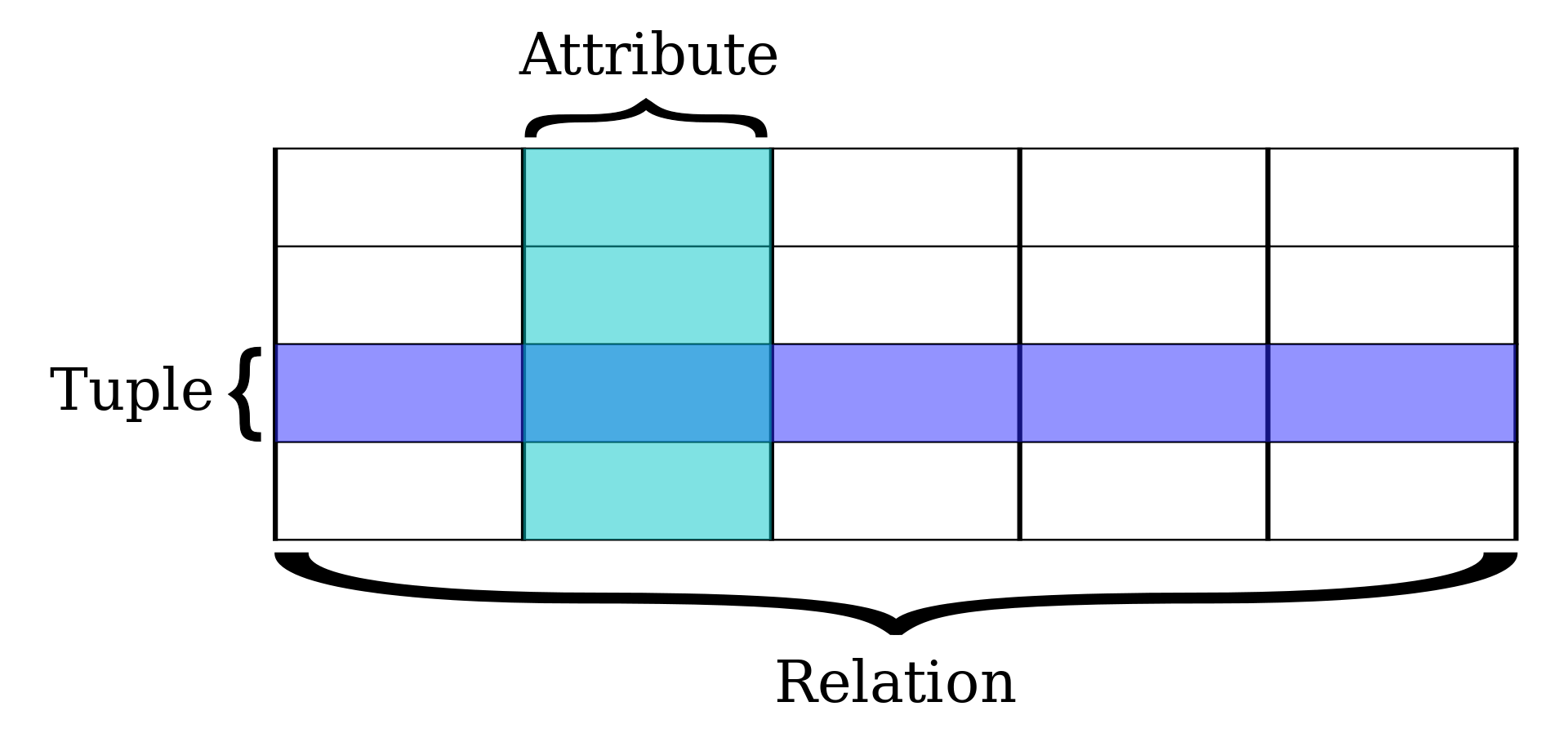
A relational database is a set of formally described related tables from which data can be accessed or reassembled. This model organizes data into one or more tables (or “relations”) of columns and rows, with a unique key identifying each row. each table/relation represents one “entity type” and these entities are connected via constrained relationships. This model is fully structured and mostly uses SQL (Structured Query Language) to retrive and manuplate data.
A single database table and its basic parts is demonstrated below. Note that each row is a set of ordered values that corresponds to a single data element. Each column in the table may be understood as an attribute, which is a common attribute, but for which each row has the data corresponding to that record. Together, the entire table consitutes a data element that can be related to other other tables.
2.1.2 Graph / Semantic databases
Semantic web is an extension of the World Wide Web standards, which promote common formats and exchange protocols on the Web. For data exchange, the fundamental Web standard is the Resource Description Framework, or RDF. Rather than being defined by tables, this “graph” or semantic structure is defined by relationship statements. RDF outlines a protocol for encoding and transmitting graph data on the web.
RDF can be queried and analyzes using a language called SPARQL (Simple Protocol and RDF Query Language). This has its own syntax, but it is similar to how relational databases use SQL (Structured Query Language) to create and build queries. In SQL relational database terms, RDF data can also be processed as a table, but with only three columns – the subject column, the predicate column, and the object column.
2.2 Conceptual foundations: RDF and Triples
The RDF defines a conceptual data model that is based on the idea of making statements about resources. Unlike a relational database, the data model defined by RDF is text-focused, and it is based on relating defined entities (as Wikidata calls them, items) that can be referred to by a Internationalized Resource Identifier (an IRI, which is nearly synonymous with a URL), and which can be connected or related to any other defined entity through a standard language. While the data structures can be complex, they rely on a basic structure called a triple, which consists of a subject and an object, which are linked together, or related, by a defined relationship called a predicate (as Wikidata calls it, a property). Here youcan read Wikipedia’s definition of a semantic triple.

The basic data statement is expressed in the form subject–predicate–object, also known as a triple. The subject denotes the resource. In Wikidata, each item, or Q node, is a triple subject. The object is usually another data entity, though it may also be a standalone value, which is related to the subject by the predicate relator. The predicate denotes traits or aspects of the resource, and expresses a relationship between the subject and the object, for example:
- The British Library is-a library
- John is-a person
- John born-in 1980
- John has-occupation engineer
Each of the above is a triple about the subject “John,” wither different predicates and objects.
As you can imagine, Wikidata has a huge number of data items (subjects), and it includes millions and millions of triple statements. RDF data are stores are also known as triplestores.
2.3 Wikidata concepts
- Items
-
Items represents things and conceps, including people, places, events,
subjects, and more. Examples mentioned previously include the British
Library or Douglas Adams. Wikidata items have identifiers that start
with letter “Q”, like
Q42for Douglas Adams.
Each item must have a label in one or more languages, optionally have alternative names and descrition. - Properties
- Properties represents attributes of the subject such occupation and have identifiers that starts with letter “P” like: P106 for Occupation.
- Claims
-
Claims are the triple statements, which combine the formation of Item
and Property and value. For example:
Douglas Adams (Q42) - occupation (P106) - comedian (Q245068). Note: value can be already stored in wikidata, therefore the bot assigns the Q number of the value instead. - Statement
- A Claim is a part of a statement, a statement also includes: References, Ranks, and Qualifiers.
- References
- Used to store the source of the claim, using properties, such stated in, qoute, and etc.
- Ranks
- A useful component to deprecate outdated claims.
- Qualifiers
- Qualifiers are basically properties but on claims rather than items.
Can you identify triple structures in library data?
Is data stored in the RDF triple format part of your work as a librarian? Take some time to think about if data stored in the RDF triple format is part of your work as a librarian. Can you give an example in the format of an RDF triple?
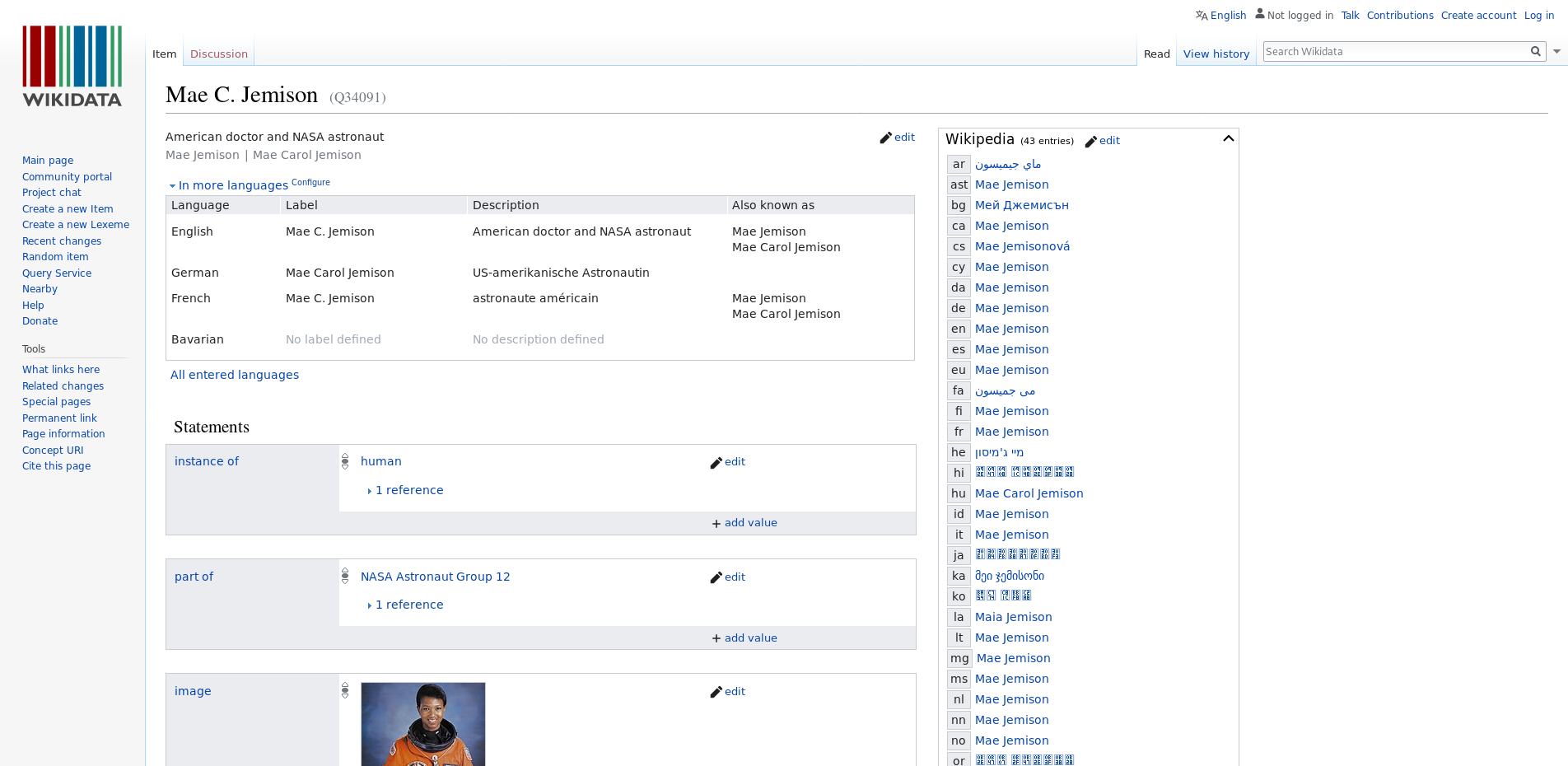
Point out one RDF triple on the Wikidata item page of former astronaut Mae Jemison.
Got to the Wikidata page of Mae Jemison and point out one RDF triple. An RDF triple consists of a subject, a predicate and an object. Can you assign the three corresponding Wikidata terms?
Go to Wikidata and either search for “Mae Jemison” or enter the ID
Q34091. In the picture below the statement “Mae C. Jemison -
part of - NASA Astronaut Group 12” is an RDF triple. 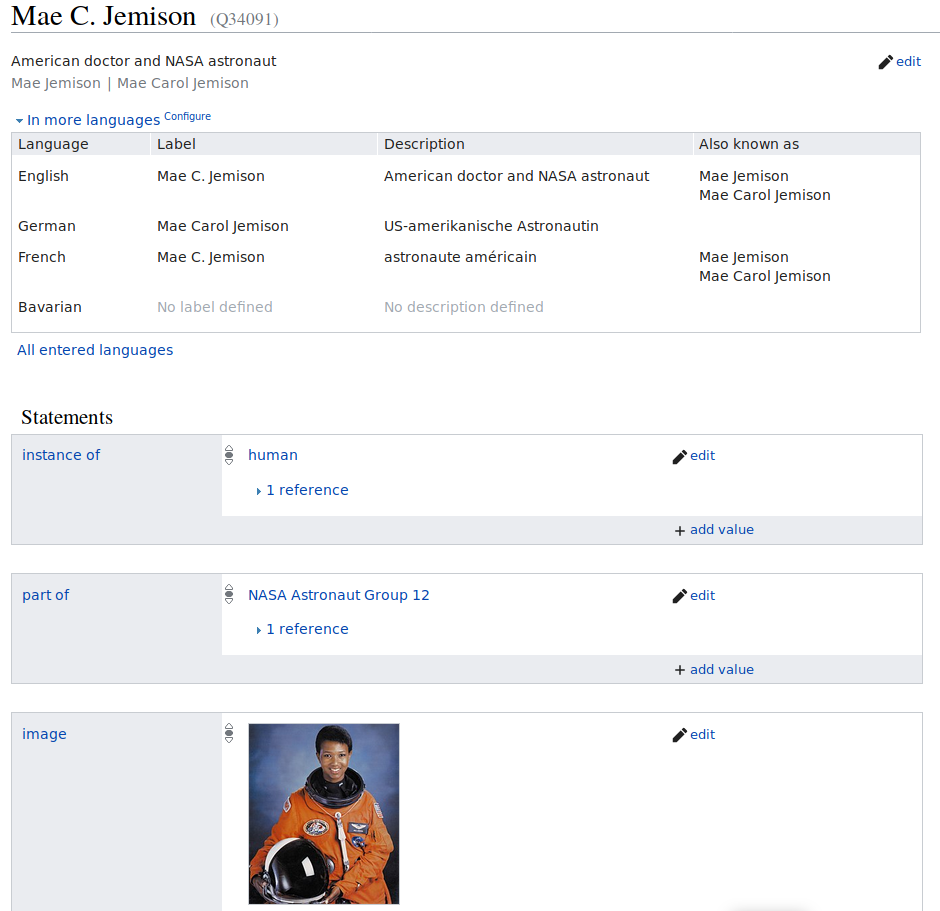
Screenshot of Wikidata Main
Page
2.4 Tools and services using Wikidata
Wikidata’s open data can be used and reused by anyone. A number of tools and services have been built on top of Wikidata’s database, demonstrating its value as a linked open data resource.
The Linked Open Data Cloud
Wikidata is part of a much larger ecosystem of linked open datasets. The Linked Open Data Cloud visualizes the connections between hundreds of open datasets on the web. Note that this visualization is updated regularly.

Scholia
Scholia is a tool built on top of Wikidata that visualizes scholarly profiles and research outputs. It has no own database but queries Wikidata directly, which means any addition to Wikidata is immediately reflected in Scholia. It is particularly useful for librarians working with research information.
Explore a Wikidata item and its Scholia profile
Part 1: Wikidata item
Go to the Wikidata page of Donna Haraway (Q253407), a feminist scholar and philosopher of science.
- What statements can you find?
- What identifiers are listed?
- What links to other Wiki projects do you see?
Part 2: Scholia profile
Now go to the Scholia profile of Alex Bateman (Q18921408), a bioinformatician with many publications in Wikidata.
- How many publications are listed per year?
- What topics does his research cover?
- Who are his most frequent co-authors?
- Can you find the academic tree and citation statistics?
InteractOA
InteractOA is another example of a web service built on top of Wikidata. It visualizes genomic RNA interaction networks based on data stored in Wikidata, linked directly to the open-access articles that describe the evidence for these interactions. It demonstrates that Wikidata can serve as a sustainable, open database for specialized scientific knowledge.
- Triples are the basic data structure of graph databases, and they are the conceptual structure of Wikidata statements.
- Wikidata items are denoted by a human-readable label and a short description, and a unique identifier that begins with a Q. These items are the subjects of linked Wikidata statements.
- Wikidata defines relationships between items, also known as triple predicates, with Wikidata properties.
- Wikidata statements can capture library information, such as relationships like creatorship, publication, aboutness, and more.
- Wikidata is part of a larger Linked Open Data ecosystem, and its data can be reused to build tools and services such as Scholia, InteractOA, and others.
Content from Introduction to editing
Last updated on 2026-04-17 | Edit this page
Estimated time: 30 minutes
Overview
Questions
- How to create and edit a Wikidata item?
Objectives
- Be able to create and edit a Wikidata entry.
- Know properties and relations, and where to find lists of approved properties and relations.
- Be able to add new statements that link to other items.
- Be aware of property constraints.
- Know community norms around Wikidata and why they are important.
- Be able to add references appropriately.
- Know what identifiers are and how to add them to a statement.
- Know different stable identifiers (e.g. ORCID for authors, DOI for works) and why makes sense to use them as properties.
- Know the correct use of properties.
3.1 Introduction
Here we will work in the test instance of Wikidata so you will not break anything. Also keep in mind that the editing history is kept in Wikidata so error can also be easily fixed there. The test instance is cleaned regularly. You can quickly figure out if you are on the Wikidata instance (colored logo) or the test version (black-and-white only).
3.2 Create new items
This exercise uses the test instance of Wikidata by default to avoid cluttering the live database with practice entries. If you want to make the exercise more hands-on, an alternative is to have learners find their own institution’s library in Wikidata and add a missing statement (e.g. coordinates, official website, or an external identifier like ISNI). This requires some preparation in advance.
Note: Based on learner feedback, the focus of this lesson has shifted towards SPARQL queries. This exercise can be kept short or skipped if time is limited.
In the following we will create new items. In order to avoid to fill Wikidata with test entries, we will use the test instance (https://test.wikidata.org/) and not the official, production version (https://wikidata.org/).
Go to the test instance at https://test.wikidata.org/
Click “Create a new Item” link on the left site. You will see a form that looks like this:
- Please fill the form. You can now add an entry about anything you want like a book, a research article or and author. We will generate an entry of Mae Jemison an American engineer, physician and NASA astronaut. You can also add yourself (if you feel famous enough). We choose “en” int the Language drop-down menue, write “Mae Jemison” in the Label field, “an American engineer, physician and NASA astronaut.” in the Description field and “Mae Carol Jemison” in the Aliases field.
- Once we are done we click click “Create”. You should see you newly created article. The URL, the adress shown in your web browser, should contain “Q” and some number that is unique for this entry at the end.
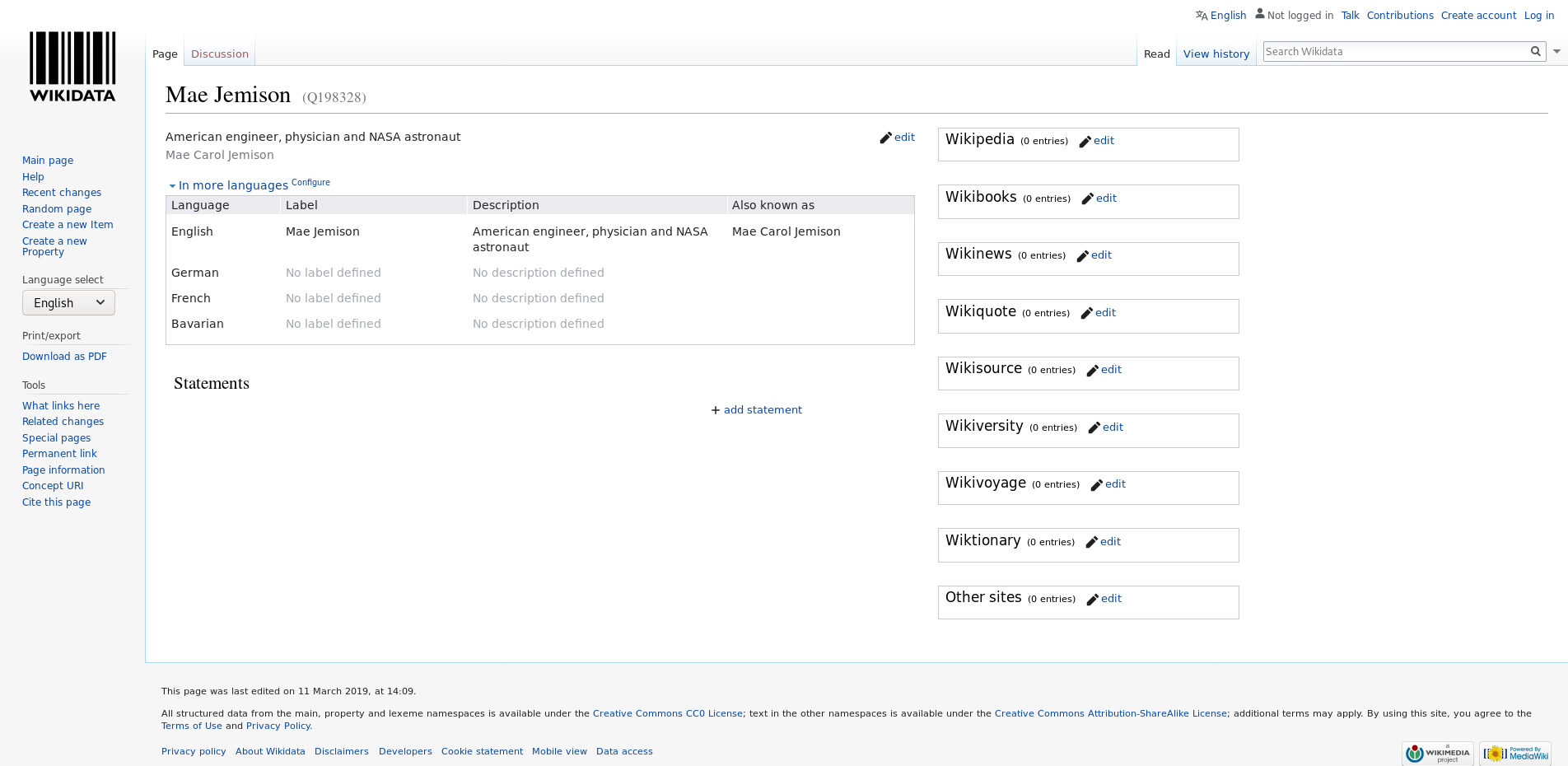
You can compare the entry that you have generated on the test instance with the current version of the item in Wikidata (Q34091).
3.3 Add Statements - birth reference
Why Wikidata uses references: Like in Wikipedia it is important that content can be verified by others to make sure it is correct and comes from a reliable source of information, such as a book, scientific publication, or newspaper article. A Reference (or source) is used to point to specific sources that back up a claim in Wikidata. A reference can be a link to a URL or an item; for example, a book. Wikidata does not aim to answer the question of whether a statement is correct, but only whether the statement appears in a reference.
Task:
-
Support a statement by reference
- Add the birth date (October 17, 1956) of Mae Jemison as a statement using property P569 “date of birth” to the “Mae X Jemison” item you created above.
- Afterwards add a reference to the satement with the following url as the source: https://www.biography.com/astronaut/mae-c-jemison
3.4 Add Statements - Add ID to Mae Jemison
Task: Support a person by it’s IDs. Give the participtants the identifiers and source page for an ID and let them add it on the Mae Jemison item on the test instance of Wikidata:
- VIAF ID
- identifier: 33699121
- source page: https://viaf.org/viaf/33699121/
- Library of Congress authority ID
- identfier: n95004729
- source page: http://id.loc.gov/authorities/names/n95004729.html
- IMDb ID
- identifier: nm0420648
- source page: https://www.imdb.com/name/nm0420648/ Site note:
- ORCID is an often used ID, in this case Mae Jemison doesn’t have one, but it’s good to mention ORCID anyway.
3.5 Norms and good practices
Wikidata has a number of community norms and best practices that are important to follow when creating and editing items.
Language settings
You can customize the languages displayed in the Wikidata interface under your user preferences. This is useful if you work with items in multiple languages.
Terminology
Wikidata uses the term “item” rather than “article” or “entry”. This reflects that Wikidata is a database of structured data, not a collection of articles like Wikipedia.
Policies for labels and descriptions
Wikidata has specific guidelines for how labels and descriptions should be written:
- Labels should be short and unambiguous.
- Descriptions should be brief and help distinguish an item from similar items.
Books and library materials
Books are a common use case for librarians working with Wikidata, but they have a relatively complex data model. Wikidata distinguishes between a work (the intellectual content) and its editions (physical manifestations). The WikiProject Books data model provides guidance on how to model books correctly.
Inventaire is an example of a tool built on Wikidata that focuses specifically on books and library materials.
- Use the test instance of Wikidata (test.wikidata.org) to practice editing without affecting the live database.
- New items require a label, description, and optional aliases; each item receives a unique Q-identifier.
- Statements link properties (e.g. P569 “date of birth”) to values and should be supported by references pointing to reliable sources.
- Identifiers such as VIAF, Library of Congress authority ID, IMDb ID, or ORCID connect a Wikidata item to external databases and increase its reliability.
- Community norms govern how labels and descriptions are written; following them ensures consistency across Wikidata.
- Wikidata distinguishes between a work and its editions — this is especially relevant for books and library materials.
Content from Advanced editing
Last updated on 2026-04-17 | Edit this page
Estimated time: 0 minutes
Overview
Questions
- How to automatically add statements with sourcemd and quickstatements?
Objectives
- Be familiar with some tools for editing, e.g. TABernacle, Wikidata Games, QuickStatements, Source MetaData or Author Disambiguator/Author resolver.
4.1 Disclaimer
The tools are under heavy development and due to that they might change or don’t work as expected. If that happens just move on to the next episode.
4.2 Introduction
So now we will work in the productive version. We will use DOI to automatically put an article into Wikidata via sourcemd. If you are familiar in Life Science you can use our example with PubMed for finding DOIs of new article, optional you can choose an journal related to your scientific field. Sourcemd gets it metadata from Crossref, also look to sourcemd:instructions
Potential open access journal:
4.3 Adding statements via sourcemd and quickstatements
Go to pubmed, scroll
down to “latest literature” and select an article: 
Save the DOI, PMID or PMCID of the article:

Go to sourcemd and paste the DOI or PMID into the search field:
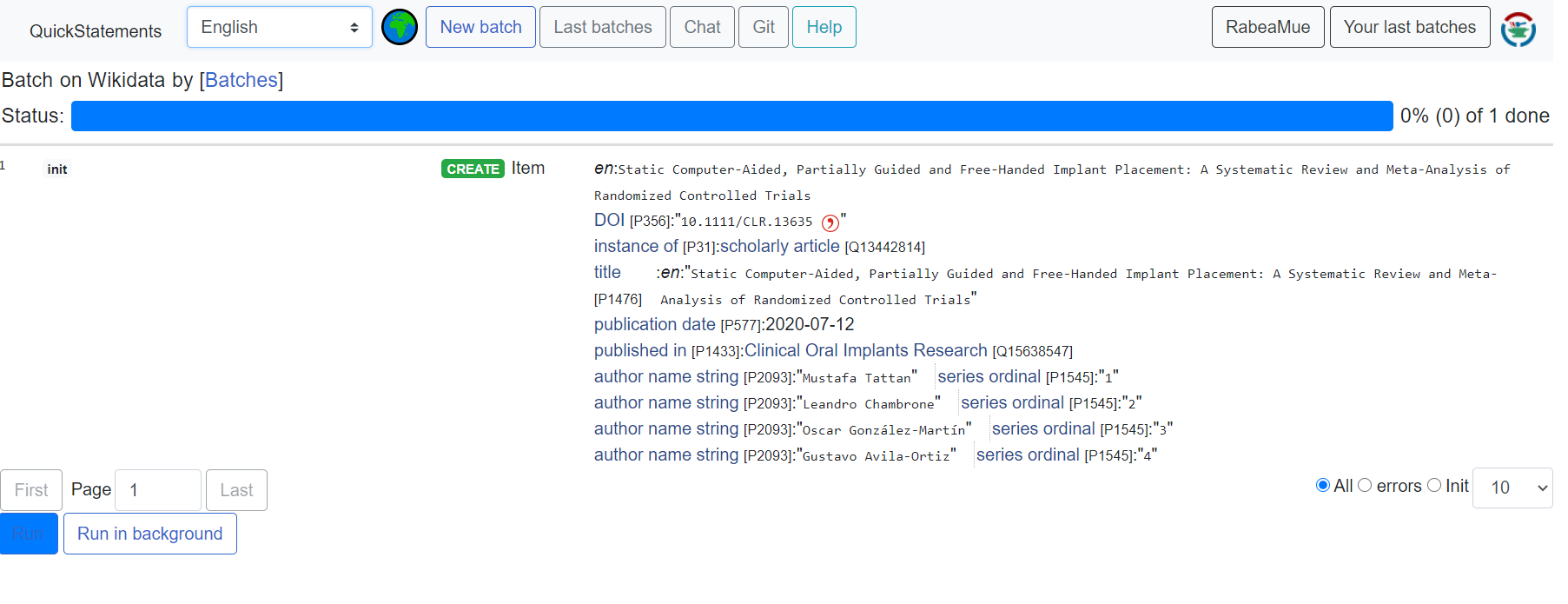
Click on “check source”. Now you can see automatically generated statements including meta data of the article like author names or date of publication. Click on “Open in QuickStatements”.
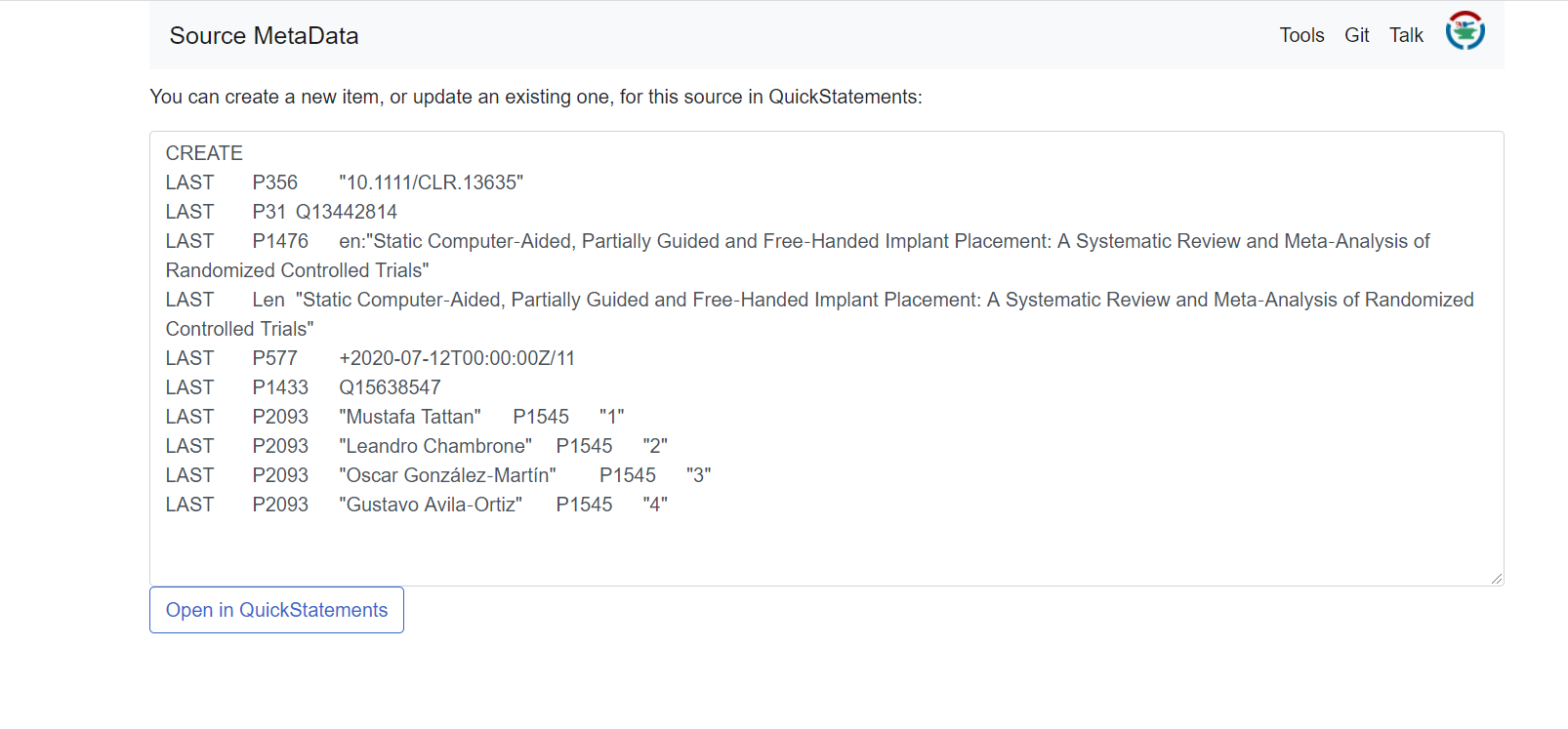
A new window with QuickStatements will pop up. Now you’ll get an overview of the new item and its statements. Confirm the changes by hitting the the “run” button:
4.4 (OPTIONAL) Converting “author strings” to “author”
When bibliographic data is imported into Wikidata in bulk, author names are often stored as plain text strings using the property author name string (P2093) rather than as linked Wikidata items using author (P50). Converting these strings to proper linked author items makes the data much more useful — for example, it enables tools like Scholia to generate complete researcher profiles.
Finding author strings
You can find author strings that need disambiguation using this query collection maintained by the Foerstner Lab:
You can also access your own Scholia profile’s curation page by
appending /missing to your Scholia author URL, e.g.:
https://scholia.toolforge.org/author/Q18921408/missing
Using the Author Disambiguator
The Author Disambiguator is a tool that helps you convert author name strings (P2093) to linked author items (P50). To use it:
- Go to https://author-disambiguator.toolforge.org/ and log in with your Wikimedia account.
- Enter an author name in the search field. Use natural order (Given name Family name).
- The tool will display a list of publications in Wikidata that have this name as an author string.
- Check the publications that belong to this author.
- Select the corresponding Wikidata author item from the list of potential matches at the bottom, or create a new one if needed.
- Click “Link selected works to author” to replace the string with a proper linked item.
This exercise works best with authors who have many publications already in Wikidata, such as researchers active in open science or life sciences communities. Encourage learners to try their own name or the name of a colleague.
- Sourcemd and QuickStatements allow you to automatically add bibliographic metadata from DOIs or PMIDs to Wikidata.
- The Author Disambiguator tool can help convert unstructured author strings to linked Wikidata items.
- Tools for advanced editing are under active development and may change or be temporarily unavailable.
Content from Introduction to querying
Last updated on 2026-04-20 | Edit this page
Estimated time: 0 minutes
Overview
Questions
- What is SPARQL?
- How to use SPARQL to query Wikidata?
- How to use Wikidata querying tools?
Objectives
- Know what a query language is, and how SPARQL differs SQL.
- Be able to use SPARQL to query Wikidata.
- Potentially be able to use a tool like TABernacle to edit based on a query.
- Have a cursory knowledge of the plethora of Wikidata querying tools and how they can be used by librarians.
- Know the purpose and usefulness of maintenance queries for identifying missing information.
- Be able to create maintenance queries.
In this episode we will learn how to query Wikidata using SPARQL, the query language for RDF data. We will start with simple queries and work our way up to more complex ones, including visualizations like maps, charts, and graphs. The Wikidata Query Service at https://query.wikidata.org/ will be our main tool throughout this episode.
There are different ways to query information in Wikidata. The simplest way is to search for an entry in Wikidata and looking up all information for that entry, e.g. search for Richard Feynmann. This search looks by default in the Q-pages as well as the P-pages. However, we can restrict a search for a property by only looking in the P-pages, e.g. if we want to look whether there is property for the ISBN we can restrict that search to properties only. Moreover, for a given entry there is always the possibility to see other pages which links to that (e.g. using it as an object), e.g. all pages linking to Richard Feynman: https://www.wikidata.org/wiki/Special:WhatLinksHere/Q39246
That is not much different from other searches you may be familiar with. However, the real potential of Wikidata as a huge knowledge graph, can be experienced through more advanced querying with the Wikidata query service where the queries have to entered in SPARQL.
% To discover Wikidata objects nearby there is the nearby search: % https://www.wikidata.org/wiki/Special:Nearby
5.1 What is SPARQL?
SPARQL is a query language for RDF data and is a W3C recommendations since 2008. The data has to be stored as triples where the object of one triple can be the subject of another triple. Thus, one can think about a huge knowledge graph, where the nodes are connected by the predicates with other nodes. For example here we see all the information about the book “The Meaning of It All” from Wikidata as a graph:
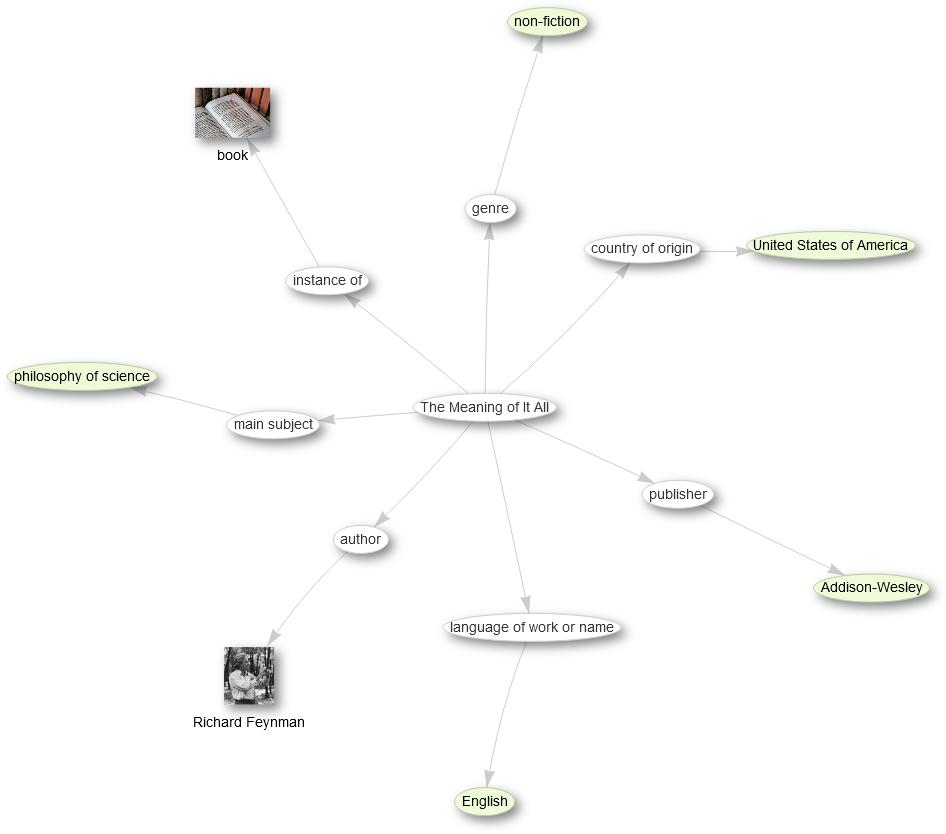 %
source: http://tinyurl.com/y267yz5q
%
source: http://tinyurl.com/y267yz5q
However, this is only the graph spanned by one item and its connected entries, which then itself also have more connections, e.g. we can open some links from the author Richard Feynman:
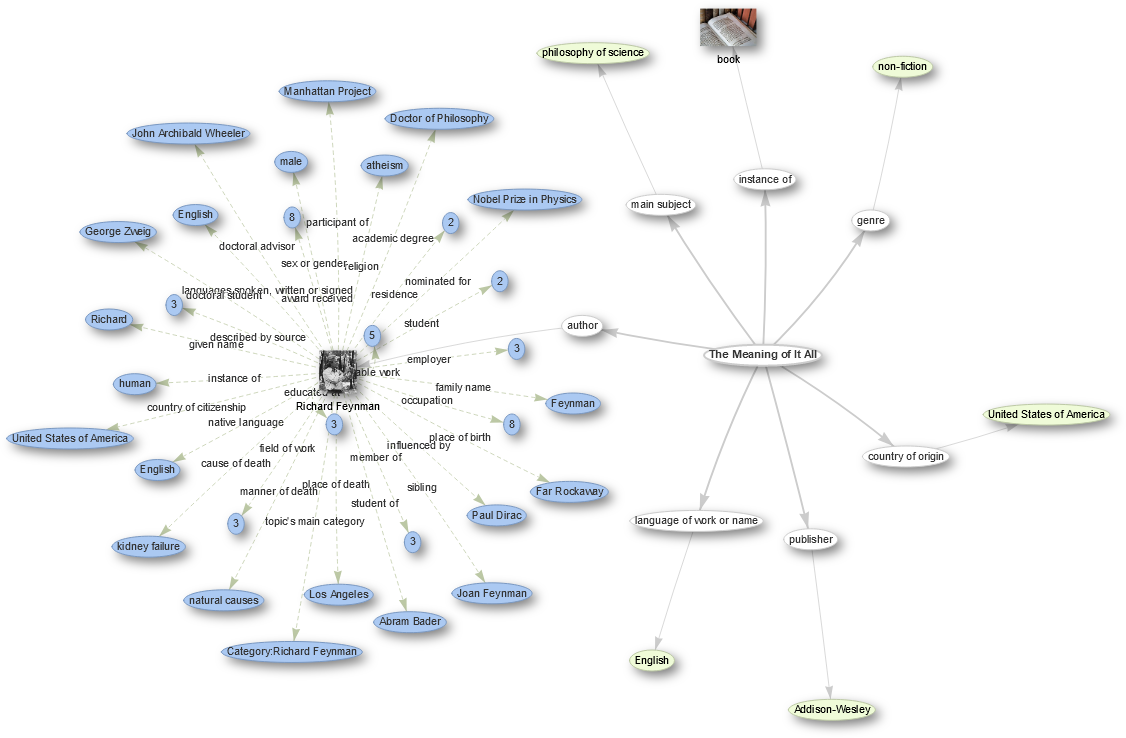 % click on that node in the above query
% click on that node in the above query
For querying data now in this knowledge graph with SPARQL we define some graph patterns which we want to search. The simplest form is a triple where we replace one of the components with a variable, which is indicated by a string starting with a question mark:
- Query for the publisher:
{ wd:Q7750812 wdt:P123 ?publisher . } - Query for the connection:
{ wd:Q7750812 ?property wd:Q353060 . } - Query for the publications from Addison-Wesley:
{ ?book wdt:P123 wd:Q353060 . }
5.2 Wikidata Query Service
The Wikidata query service can be found at https://query.wikidata.org/. There is the main window on the right to formulate your query in SPARQL. On the left there is the query helper and at the bottom the result will show up.
We will only cover here SELECT-statements and start by
typing
SELECT * WHERE {
}Hint It is enough to start typing “SELECT” and then use the auto-completion with Ctrl+Space.
Inside the parenthesis you can then place the statements describing the graph pattern you are looking for.
Exercise: Your first SPARQL query
Write your first SPARQL query for the publisher of the above mentioned book by copying the part from above point inside a SELECT-statement.
SELECT * WHERE {
wd:Q7750812 wdt:P123 ?publisher .
}Showing labels to Q-numbers
By default, SPARQL queries return Q-numbers instead of human-readable
labels. To show labels, add the SERVICE wikibase:label
block to your query:
SELECT ?item ?itemLabel
WHERE {
?item wdt:P31 wd:Q7075.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}The [AUTO_LANGUAGE] placeholder automatically uses your
browser’s language setting, with English as a fallback.
Namespaces and Prefixes
Prefixes are short abbrevations in the Wikidata Query Service. Some prefixes in Wikidata are: wd, wdt, p, ps, bd, etc.
Example:
SELECT ?item ?itemLabel
WHERE
{
?item wdt:P50 wd:Q23434.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}Items should be prefixed with wd: and properties with wdt: .
Namespaces in Wikidata are:
- Main namespace
- Property
- Wikidata: it is for information and discussions about Wikidata itself. etc.
More conditions
You can combine multiple conditions in a single query. Here is an example that finds books published by Addison-Wesley authored by Richard Feynman:
SELECT ?book ?bookLabel WHERE {
?book wdt:P31 wd:Q571. # instance of book
?book wdt:P123 wd:Q353060. # published by Addison-Wesley
?book wdt:P50 wd:Q39246. # authored by Richard Feynman
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}Useful modifiers:
-
LIMIT 10— restrict results to 10 rows -
ORDER BY DESC(?date)— sort results by date, newest first -
FILTER(YEAR(?date) > 2000)— filter by year -
OPTIONAL { ?item wdt:P18 ?image }— include a field only if it exists
How to visualize your query
Manual visualization in the results window:
Start by opening the results window. In the results pane, click the “Table” button and choose the type of visualization you want. This way, you can try different ways of visualizing your data without having to change the query code.
Automated visualization with #defaultView:
For an easy start, add the #defaultView: snippet at the beginning of your query. This method ensures that your results will be automatically visualized in a predefined style. This will save you time without having to manually adjust the result window after each query. This method is useful for queries where you already know which visualization types you want to use.
5.3 Try examples
Enough theory! it’s time to get hands-on. Let’s start with a simple example. Literally everyone likes cats, right? So lets search for them in the Wikidata database.
Cats example
SELECT ?item ?itemLabel
WHERE
{
?item wdt:P31 wd:Q146. # Must be of a cat
SERVICE wikibase:label { bd:serviceParam wikibase:language "en,[AUTO_LANGUAGE]". } # Helps get the label in your language, if not, then en language
}Alright! So we found all the cats. But I am pretty sure that I have seen pictures of cats somewhere in Wikipedia or Wikidata. Is there a way to display the images in the Wikidata query service? The simple answer is yes! Let me show you how to do it.
Cats pictures
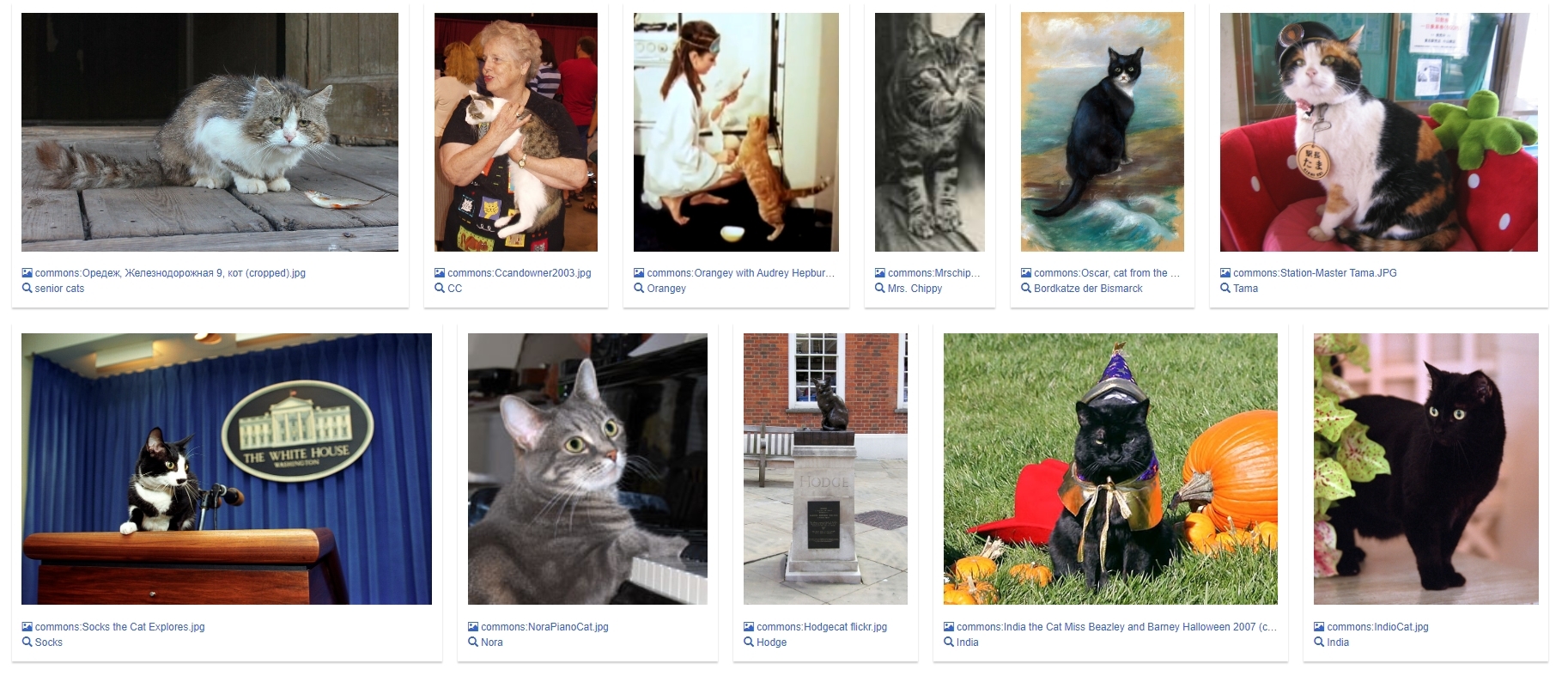
In the first step, we searched for cats. It is also possible to search for images in Wikidata, if they are available. The Wikidata query service offers several types of visualization. The image grid is a good way to display images.
#defaultView:ImageGrid
#Normally, the default output is a table, but with the defaultView we can directly specify that the results should be displayed in a grid
SELECT ?item ?itemLabel ?itemPic
#Show me the item, label and the picture of it
#The result list will look like this (wd:Q123185365/senior cats/ commons:Оредеж, Железнодорожная 9, кот (cropped).jpg)
WHERE
{
?item wdt:P31 wd:Q146. #The item of this search is a cat
?item wdt:P18 ?itemPic. #Show me only cats with pictures. If you want to include very cats in your search, you need to place the Option{} function in front
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
#Helps to get the label in English. If not, yours will be selected automatically
}
Wow that was quit a lot of Code, hasnt it. lets break it down so you understand the synatx better.
Lets move on to another example
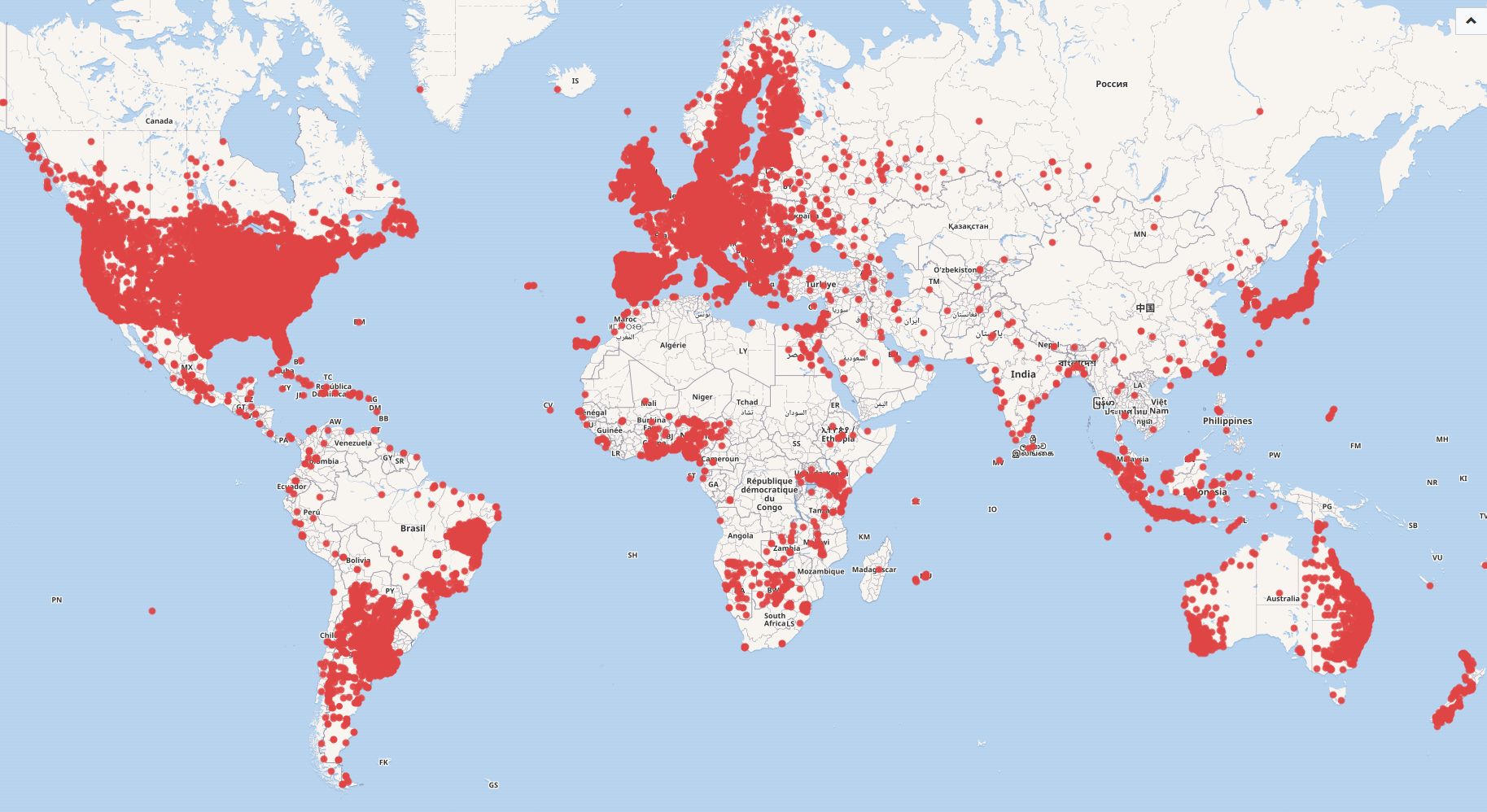
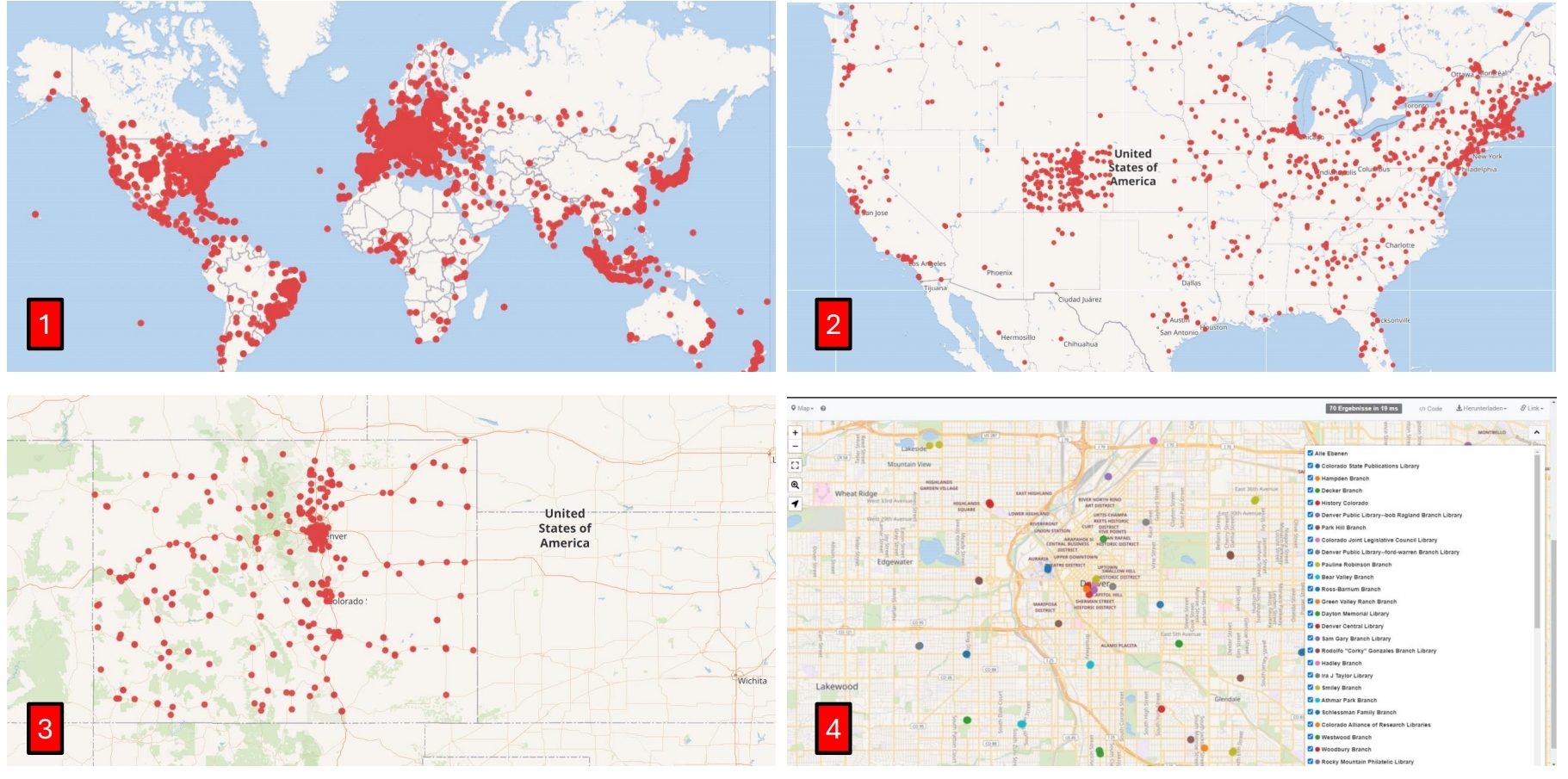
Worldmap of libraries
#defaultView:Map
#Display the results as a Map
SELECT distinct *
#Display all available geographic coordinates
WHERE {
?item wdt:P31 wd:Q7075; #Define the item as a library ";"(and) define the geographic coordinates of item as ?geo
wdt:P625 ?geo.
}
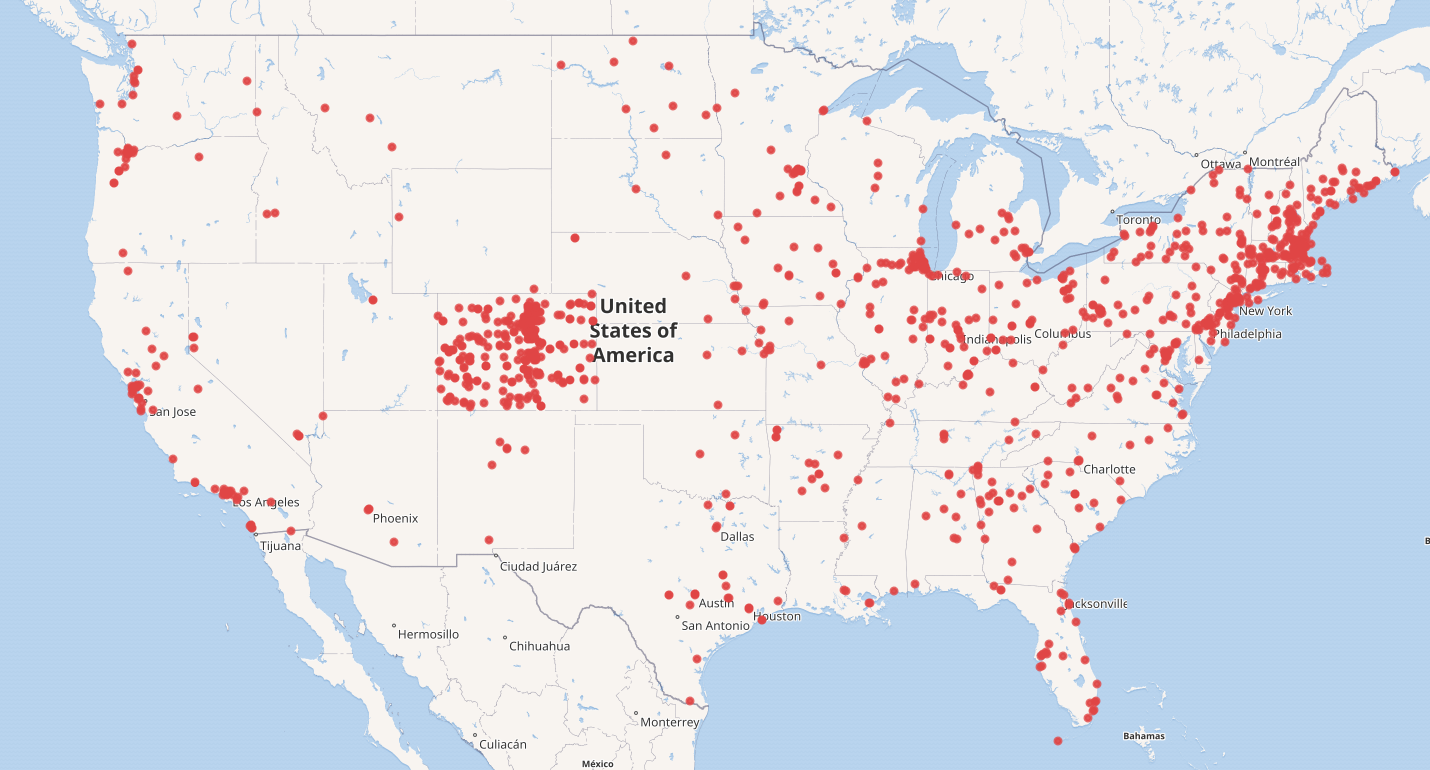
Map of libraries in the USA
#defaultView:Map
#Display the results as a Map
SELECT ?itemLabel ?geo
#Display the label and the geographical coordinates of the item
WHERE {
?item wdt:P31 wd:Q7075. #Define the item as a library
?item wdt:P625 ?geo. #bind the geographic coordinates as ?geo
?item wdt:P17 ?country. #bind the country of item as ?country
FILTER(?country = wd:Q30) #Use Filter to set Country to wd:Q30(U.S.A)
SERVICE wikibase:label { bd:serviceParam wikibase:language "en,[AUTO_LANGUAGE]". }
#Helps to get the label in English. If not, yours will be selected automatically
}
Map visualization toolbox for libraries
#defaultView:Map
#Display the results as a Map
#the main query-----------------------------------------------------------------------
SELECT DISTINCT ?itemLabel ?geo #(?itemLabel AS ?layer)
#Show the label and geographic coordinates of the item
#Remove the „#“ before „(?itemLabel AS ?layer)“ to filter the result list.
WHERE {
?item wdt:P31 wd:Q7075; #Define the item as a library
wdt:P625 ?geo. #Get the Coordinates of the library
#Advanced Query Options-----------------------------------------------
#Bind the attributes you need to filter them later.
?item wdt:P17 ?country. #Bind the country of item to ?country
?item wdt:P131 ?stateORcity. #Bind the territory of item to ?stateORcity
#Filter---------------------------------------------------------------
#Select only one filter at a time to filter between country, state, and city.
#FILTER(?country = wd:Q30) #Set ?country to U.S.A(wd:Q30)
#FILTER(?stateORcity = wd:Q1261) #Set ?StateOrCity to Colorado(wd:Q1261)
#FILTER(?stateORcity = wd:Q16554) #Set ?StateOrCity to Denver(wd:Q16554
#--------------------------------------------------------------------
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
#Helps to get the label in English. If not, yours will be SELECTed automatically
}
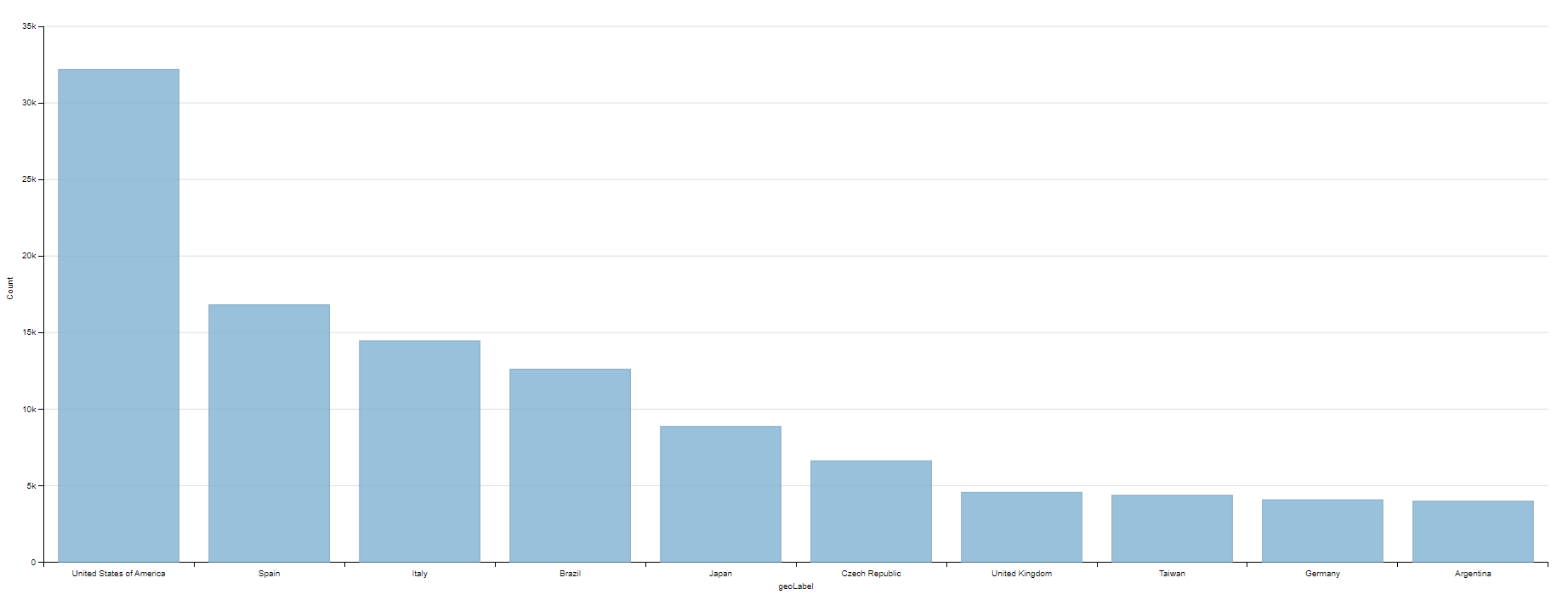
Count of libraries per Country
#defaultView:BarChart
#Display the results as a Bar Chart
SELECT distinct ?country ?countryLabel (COUNT(?item) as ?Count)
#Show me the genre, the genre label, and count the available books as a new label ?bookCount
#The result list will look like this (wd:Q213051/Non-Fiction/252)
WHERE {
?item wdt:P31 wd:Q7075; #Define the item as a library ";"(and) define the country of item as ?country
wdt:P17 ?country.
SERVICE wikibase:label { bd:serviceParam wikibase:language "en,[AUTO_LANGUAGE]". }
#Helps to get the label in English. If not, yours will be selected automatically
}
Group by ?geo ?geoLabel
#Aggregate with the group function
Order by DESC(?Count)
#Order result list by variable ?count in descending order
LIMIT 10
#Limit the shown results down to 10.
Books weight by genre Number of available books weighted by genre.
#defaultView:BubbleChart
#Display the results as a Bubble Chart
SELECT ?genre ?genreLabel (COUNT(?book) as ?bookCount)
#Show me the genre, the genre label, and count the available books as a new label ?bookCount
#The result list will look like this (wd:Q213051/Non-Fiction/252)
WHERE
{
?book wdt:P31 wd:Q571. #Searched item is a book
?book wdt:P136 ?genre. #Get the attribute genre form item
SERVICE wikibase:label { bd:serviceParam wikibase:language "en,[AUTO_LANGUAGE]". }
#Helps to get the label in English. If not, yours will be selected automatically
}
GROUP BY ?genre ?genreLabel
#Aggregate with the group function
LIMIT 15
#Limit the shown results down to 15.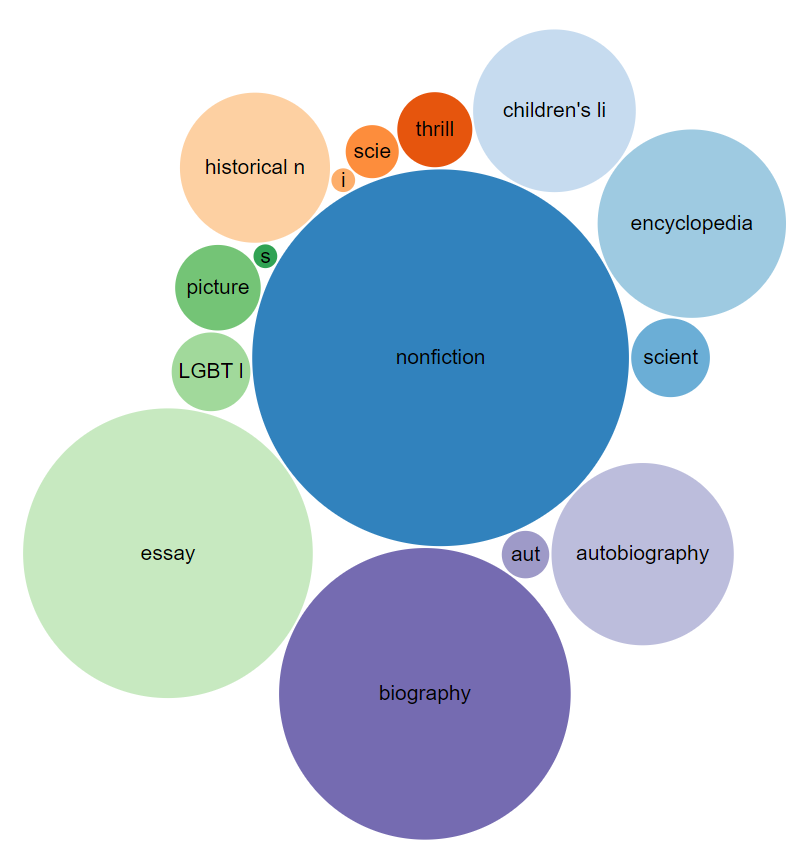
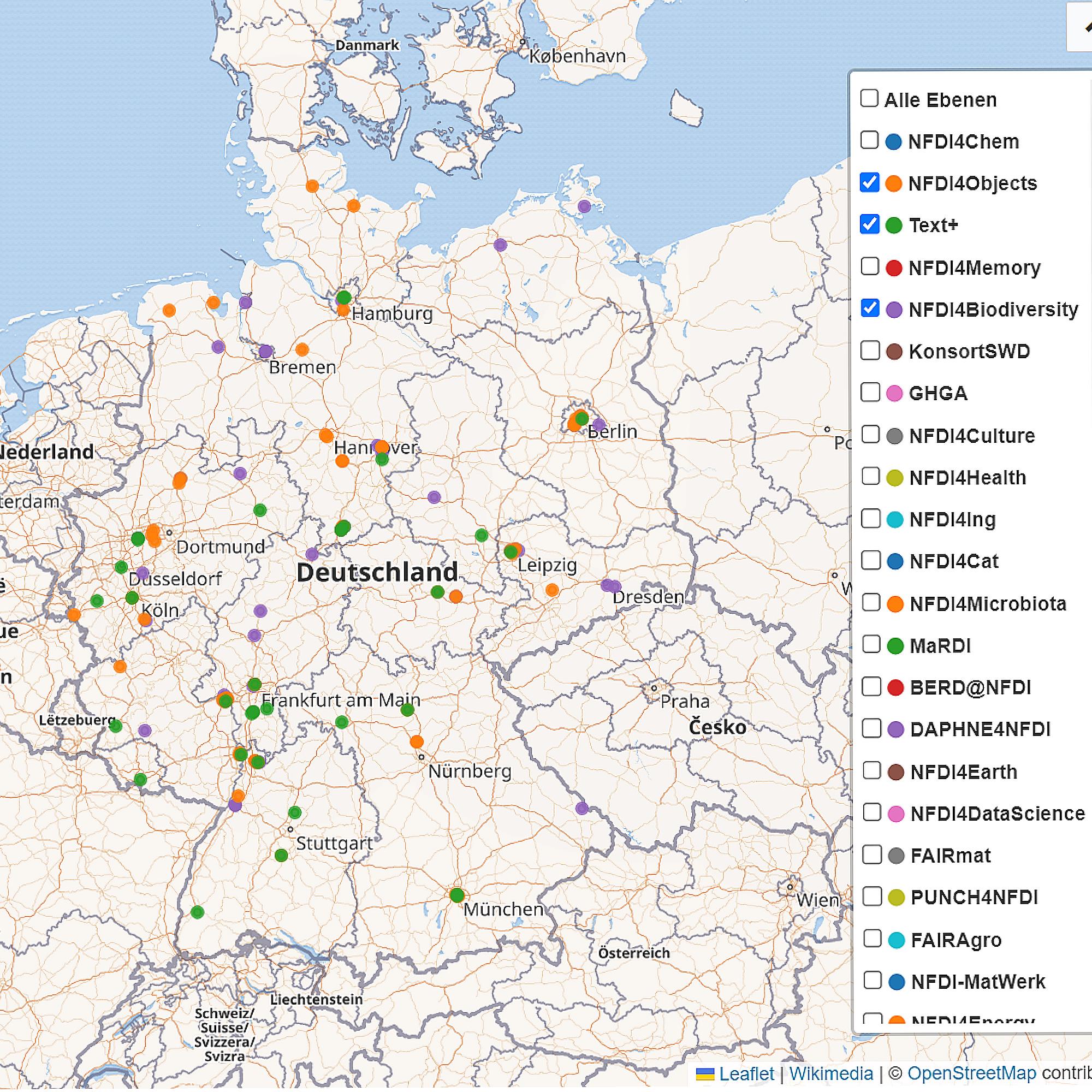
Map of NFDI Consortia in Germany
#defaultView:Map
#Display the results as a Map
SELECT DISTINCT ?affiliateLabel ?affiliatepicture ?coordinates ?NFDILabel (?NFDILabel AS ?layer)
#Show me the label, image, and coordinates of the affiliate parties.
#Show me the NFDI label as well, using the NFDILabel as a layer filter.
#The layer filter lets you choose which NFDI to display on the map.
#The result list will look like this (Deutsche Nationalbibliothek/commons:DNB.svg/NFDI4Culture/Point(8.683333333 50.131111111))
WHERE
{
?NFDI wdt:P31 wd:Q98270496. #Searched item is an accepted NFDI
?NFDI wdt:P1416 ?affiliate. #Get the affiliates of the accepted NFDI.
?affiliate wdt:P625 ?coordinates. #Get the coordinates of the affiliate parties
OPTIONAL { ?affiliate wdt:P17 ?country } #Get attribute country if available
OPTIONAL { ?affiliate wdt:P154 ?affiliatepicture } #Get attribute picture if available
FILTER(?country = wd:Q183) #Use Filter to set country to wd:Q183(Germany)
SERVICE wikibase:label { bd:serviceParam wikibase:language "en,[AUTO_LANGUAGE]" . }
#Helps to get the label in English. If not, yours will be selected automatically
}
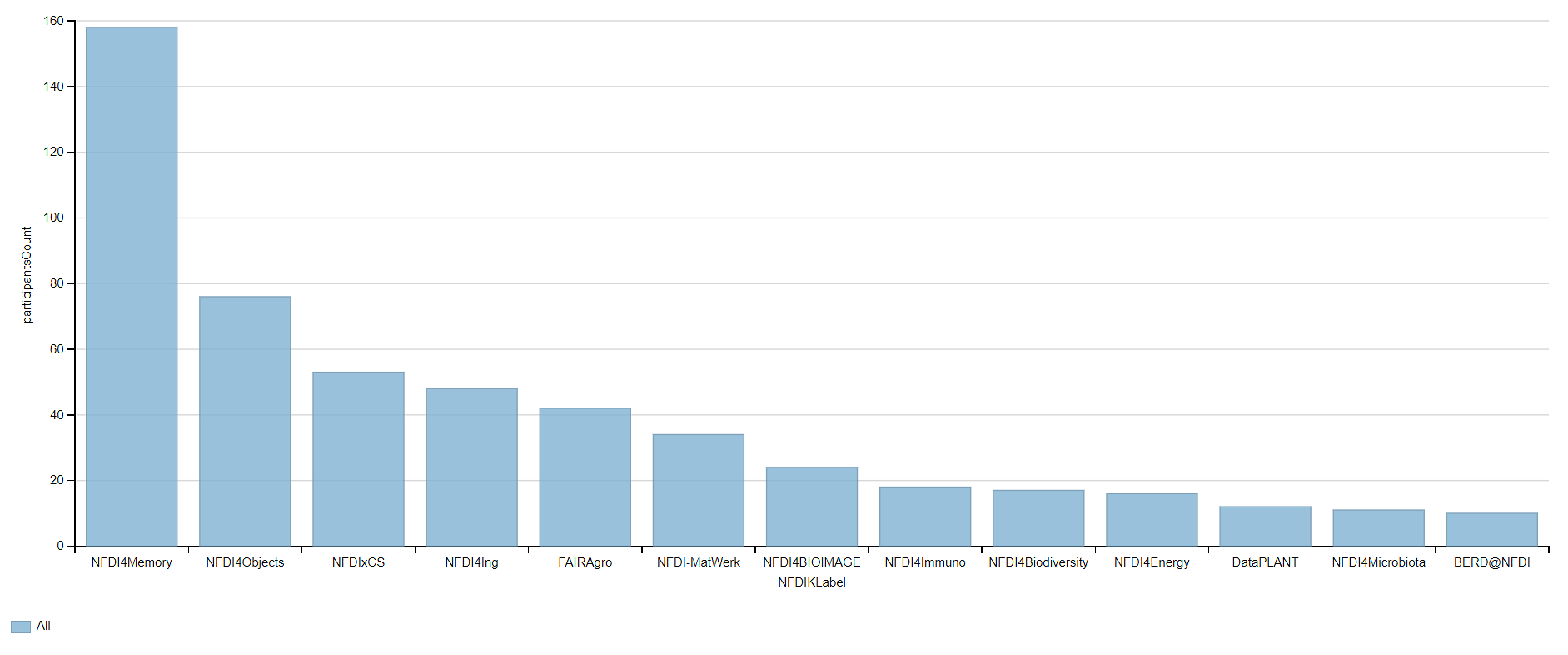
Number of participants in NFDI consortia
#Number of participants in NFDI consortia
#defaultView:BarChart
#Use the bar chart as the visualization type and give me the results immediately in the form of a bar chart.
SELECT DISTINCT ?NFDIKLabel (COUNT(DISTINCT ?participants ) as ?participantsCount)
#Give me the unique (no double entries) names of the accepted NFDIK consortia.
#Count the participants using the COUNT function and return the number of participants as a new variable ?participantsCount.
WHERE
{
?NFDIK wdt:P31 wd:Q98270496. #Give me all accepted NFDI consortia.
?NFDIK wdt:P710 ?participants. #Show me the all participants of this NFDI consortium.
#Attention: Not all consortia are listed here, but only those that have an entry participants in Wikidata.
#Participants can be researchers, research institutions, universities, companies and many more.
SERVICE wikibase:label { bd:serviceParam wikibase:language "en,[AUTO_LANGUAGE]" . }
#Helps to get the label in English. If not, yours will be selected automatically
}
GROUP BY ?NFDIKLabel
#Group by NFDIK
HAVING (?participantsCount > 4)
#Show me only NFDI consortia that have more than four registered participants.
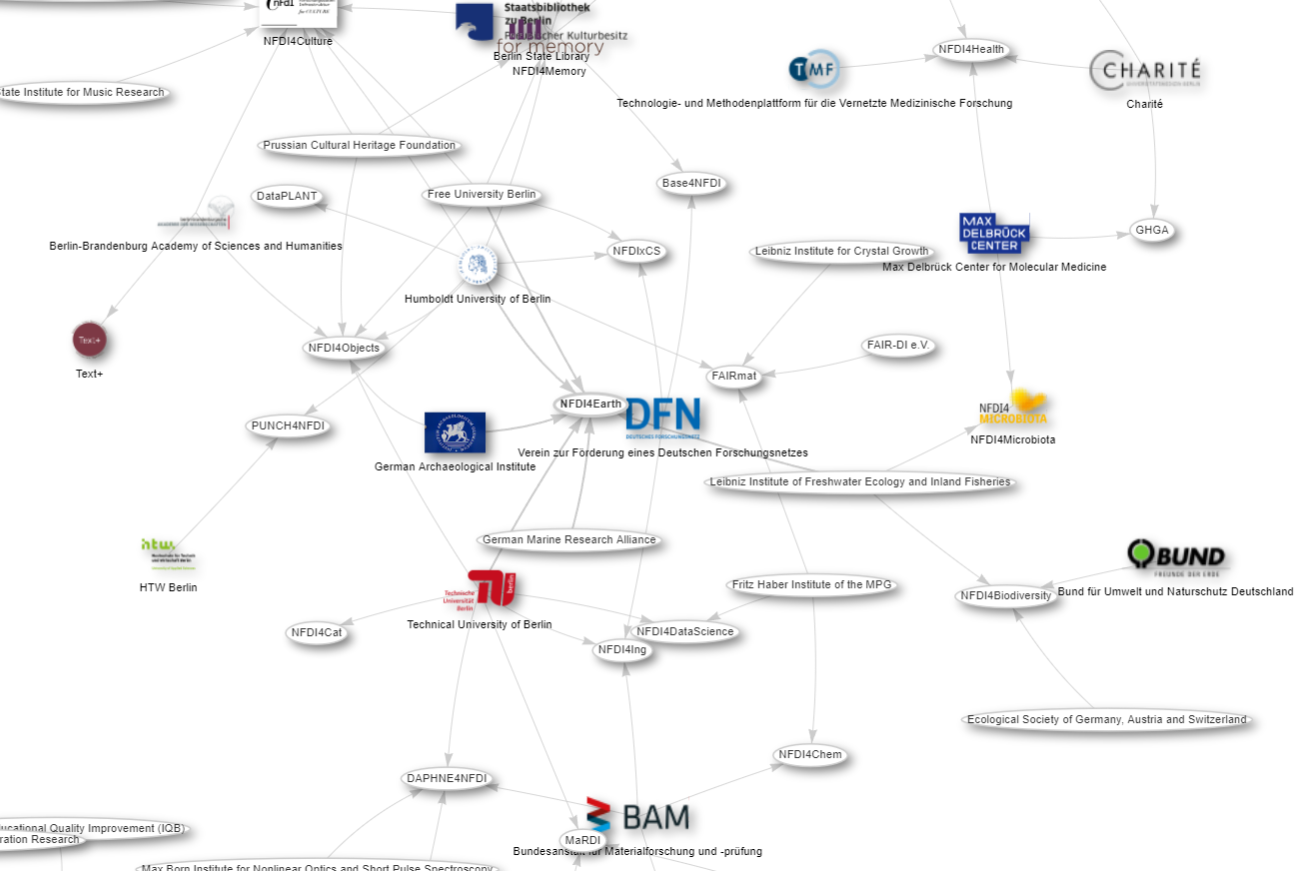
NFDI Consortia in Berlin, Germany
#defaultView:Graph
#Use the graph as the visualization type
SELECT ?affiliate ?affiliateLabel ?affiliatepicture ?NFDIK ?NFDIKLabel ?NFDIKpicture
#Give me the label and the pictures of the affiliated parties of the accepted consortia of the NFDIK.
#Give me label and pictures of accepted NFDIK consortia.
WHERE
{
?NFDIK wdt:P31 wd:Q98270496. #Get me all accepted NFDI consortia.
?NFDIK wdt:P1416 ?affiliate. #Get the affiliates of the accepted NFDI.
?affiliate wdt:P131 ?location. #Provide me with the location of the affiliated parties.
FILTER(?location = wd:Q64) #Set the location to Berlin.
OPTIONAL { ?affiliate wdt:P154 ?affiliatepicture } #Give me the pictures of the affilated partner, if available.
OPTIONAL { ?NFDIK wdt:P154 ?NFDIKpicture } #Give me the pictures of the NFDI, if available.
SERVICE wikibase:label { bd:serviceParam wikibase:language "en,[AUTO_LANGUAGE]" . }
#Helps to get the label in English. If not, yours will be selected automatically
}
scholarly articles by Alex Bateman
SELECT ?item ?itemLabel ?journalLabel
WHERE
{
?item wdt:P31 wd:Q13442814.
?item wdt:P50 wd:Q18921408.
?item wdt:P1433 ?journal.
SERVICE wikibase:label { bd:serviceParam wikibase:language "en,[AUTO_LANGUAGE]". }
}Russian poets
SELECT ?item ?itemLabel ?place ?placeLabel ?coord
WHERE
{
?item wdt:P31 wd:Q5.
?item wdt:P106 wd:Q49757.
?item wdt:P19 ?place.
?place wdt:P17 wd:Q159.
?place wdt:P625 ?coord
SERVICE wikibase:label { bd:serviceParam wikibase:language "en,[AUTO_LANGUAGE]". }
}chemicals example
SELECT ?item ?itemLabel WHERE {
?item wdt:P31 wd:Q11173, wd:Q12140.
SERVICE wikibase:label { bd:serviceParam wikibase:language "en,[AUTO_LANGUAGE]". }
}SELECT ?item ?itemLabel ?struc ?formula
WHERE {
?item wdt:P31 wd:Q11173, wd:Q12140.
?item wdt:P117 ?struc.
?item wdt:P274 ?formula
SERVICE wikibase:label { bd:serviceParam wikibase:language "en,[AUTO_LANGUAGE]". }
}SELECT ?item ?itemLabel ?formula ?mass ?struc
WHERE {
?item wdt:P31 wd:Q11173, wd:Q12140.
?item wdt:P117 ?struc.
?item wdt:P274 ?formula.
?item wdt:P2067 ?mass.
SERVICE wikibase:label { bd:serviceParam wikibase:language "en,[AUTO_LANGUAGE]". }
}
ORDER BY DESC(?mass)
LIMIT 10People born in Berlin filtered by year 1970
SELECT ?item ?itemLabel ?dob
WHERE
{
?item wdt:P31 wd:Q5.
?item wdt:P19 wd:Q64.
?item wdt:P569 ?dob.
FILTER(YEAR(?dob) = 1970)
SERVICE wikibase:label { bd:serviceParam wikibase:language "en,[AUTO_LANGUAGE]". }
}5.4 More Advanced queries
Here are some more advanced query patterns that are particularly useful for library use cases.
Federated queries and subqueries
You can use subqueries to pre-filter data before the main query processes it, which can significantly speed up complex queries:
SELECT ?item ?itemLabel ?authorLabel WHERE {
?item wdt:P31 wd:Q13442814. # scholarly article
?item wdt:P50 ?author.
?author wdt:P108 wd:Q160302. # affiliated with a specific institution
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}
LIMIT 20Maintenance queries
Maintenance queries help identify items that are missing information. These are useful for librarians who want to improve data quality:
# Libraries without coordinates
SELECT ?item ?itemLabel WHERE { ?item wdt:P31 wd:Q7075. # instance of library FILTER NOT EXISTS { ?item wdt:P625 ?coord } SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". } } LIMIT 20# Scholarly articles without a DOI
SELECT ?item ?itemLabel WHERE { ?item wdt:P31 wd:Q13442814. # scholarly article FILTER NOT EXISTS { ?item wdt:P356 ?doi } SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". } } LIMIT 20Further resources
- Wikidata Query Service in Brief (PDF)
- SPARQL tutorial on Wikidata
- SPARQL lecture slides, University of Mannheim
- SPARQL is a query language for RDF data that allows you to search across the entire Wikidata knowledge graph.
- The Wikidata Query Service at https://query.wikidata.org/ provides an interface to write and run SPARQL queries with auto-completion.
- Results can be visualized in multiple ways including tables, maps, charts, and graphs using the Display menu or #defaultView.
- It is good practice to modify existing example queries rather than writing queries from scratch.