Content from Introduction to Library Carpentry
Last updated on 2023-09-18 | Edit this page
Overview
Questions
- How can The Carpentries & Library Carpentry help libraries meet the data and software needs of their communities and staff?
Objectives
- Learn about campus trends in data science.
- Understand data science challenges and opportunties for libraries.
- Learn how The Carpentries & Library Carpentry works.
- See what libraries are doing with The Carpentries & Library Carpentry.
- Understand how you can get involved and about training at your institution.
Introduction to Library Carpentry – Teaching Data Science Skills
Who you are?
Start with your background, role at your institution, and what role (or desired role) you have in the Library Carpentry/Carpentries community.
Our aim is to help libraries become data and software savvy.
Outline
- Campus trends in data science
- Challenges for libraries
- Opportunities for libraries
- The Carpentries - How it works
- Library Carpentry - What libraries are doing
- How to get involved
- Training at your institution
Campus trends
With the emergence of our ability to generate increasing amounts of data, research and work in almost every domain has a data and computational component, including the whole new field of data science.
Libraries are guided by the needs of their communities…
- Surveys point to an increasing need from researchers for data & software skills
- Researchers do not receive the training they need in software best practices
- Many universities are integrating data science into the curriculum
- Industry is looking to hire more data savvy candidates
- Early career researchers are looking for career advancement opportunities
Unmet needs
According to Barone L, Williams J and Micklos D. Unmet Needs for Analyzing Biological Big Data: A Survey of 704 NSF Principal Investigators (2017):
- Nearly 90% of BIO PIs said they are currently/will soon be analyzing large data sets
- Majority of PIs said their institutions are not meeting 9 of 13 needs
- Training on integration of multiple data types (89%), on data management and metadata (78%), and on scaling analysis to cloud/HPC (71%) were the 3 greatest unmet needs
- Data storage and HPC ranked lowest on their list of unmet needs
- The problem is the growing gap between the accumulation of big data—and researchers’ knowledge about how to use it effectively
In a survey of biology NSF PIs, the top 3 unmet needs are around training
Importance of research software & training
- 92% of academics use research software
- 69% say that their research would not be practical without it
- 56% develop their own software (worryingly, 21% of those have no training in software development)
S.J. Hettrick et al, UK Research Software Survey 2014 [Data set]. Zenodo. http://doi.org/10.5281/zenodo.14809
Educational Pathways
Academic institutions should provide and evolve a range of educational pathways to prepare students for an array of data science roles in the workplace.
National Academies of Sciences, Engineering, and Medicine. 2018. Data Science for Undergraduates: Opportunities and Options. Washington, DC: The National Academies Press. https://doi.org/10.17226/25104.
Moore-Sloan Data Science Environments
On our campuses, library spaces have been transformed—among other things—into campus centers for data science research, training, and services, with open floor plans and furnishings that are adaptable to a range of activities that promote and support data science research and learning.
“Creating Institutional Change in Data Science” Chronicles of Higher Ed, Mar 2018
Rise of data science initiatives in academia
From the Data Science
Community Newsletter by Noren & Stenger:
Brigham Young University, Caltech, Carnegie Mellon, College of
Charleston, Columbia, Cornell, Dartmouth UMass, George Mason University,
Georgetown University, Georgia Tech, Harvard, Illinois Wesleyan
University, Johns Hopkins, Mid America Nazarene University, MIT,
Northeastern University, Northern Kentucky University, Northwestern,
Northwestern College in Iowa, Ohio State University, Penn State
University, Princeton, Purdue, Stanford, Tufts University, UC Berkeley,
UC Davis, UC Irvine, UC Merced, UC Riverside, UC San Diego, UCLA, UIUC,
University of Iowa, University of Michigan, University of Oregon,
University of Pennsylvania, University of Rochester, University of San
Francisco, University of Warwick, University of Washington, UT Austin,
UW Madison, Vanderbilt University, Virginia Tech, Washington University
in St. Louis, Middle Tennessee State University, NYU, Amherst College,
Brown, CU Boulder, Duke, Illinois Institute of Technology, Lehigh
University, Loyola University - Maryland, Rice University, SUNY at Stony
Brook, UC Santa Barbara, UC Santa Cruz, UCSF, UMass Amherst, UNC -
Wilmington, University of Vermont, University of Arizona, University of
British Columbia, University of Chicago, University of Virginia, USC,
Worchester Polytechnic, Yale
70 and counting…
Investing in America’s data science and analytics talent
- 69% of business leaders in the United States will prefer job applicants with data skills by 2021.
- 23% of college and university leaders say their graduates will have those skills.
April 2017 Business-Higher Education Forum (BHEF) report titled “Investing in America’s Data Science and Analytics Talent: The Case for Action.”
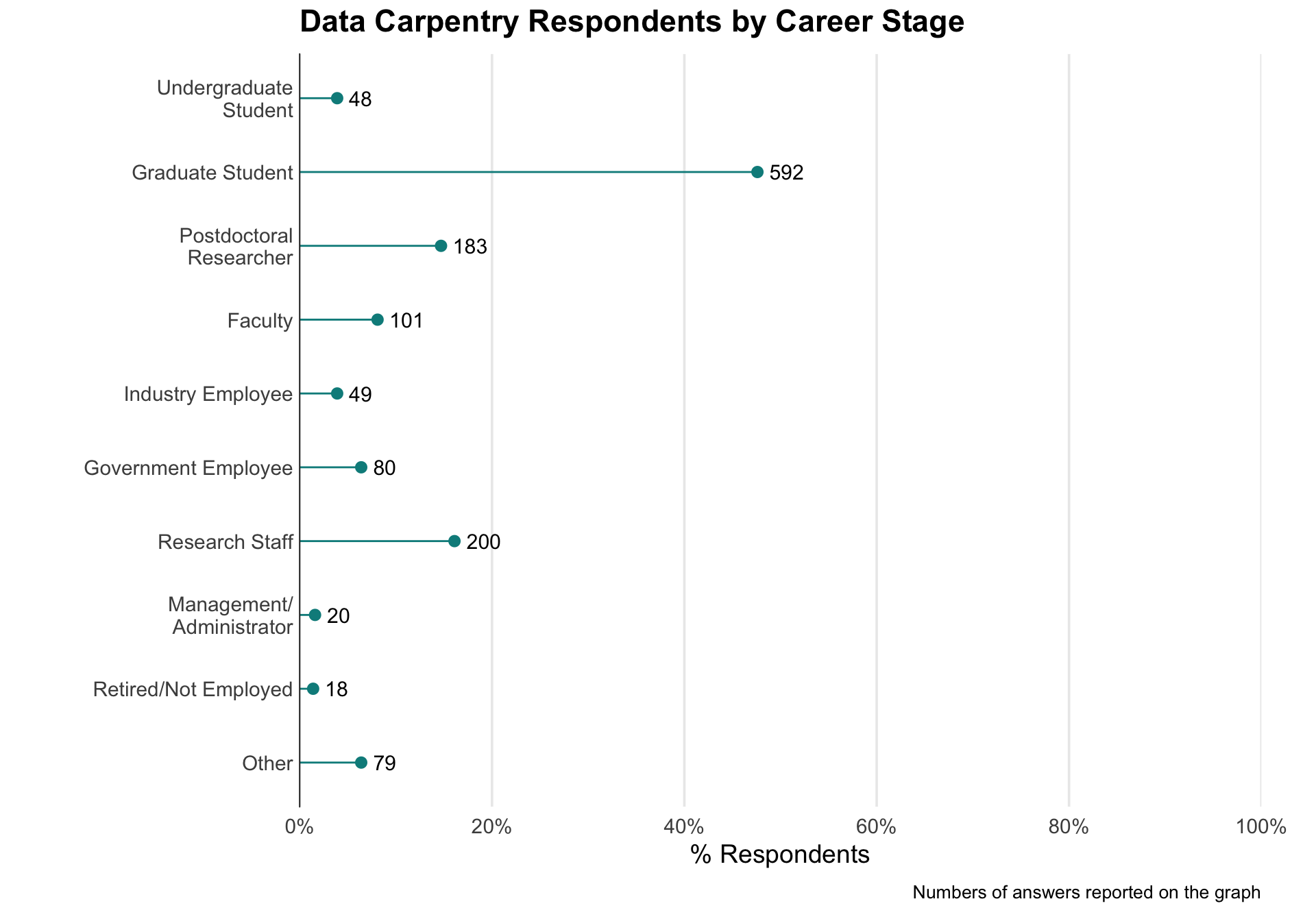
66% of the Data Carpentry workshop attendees are early career.
Analysis of Software and Data Carpentry’s Pre- and Post-Workshop Surveys https://doi.org/10.5281/zenodo.1325463
Our path to better science in less time using open science tools
Reproducibility has long been a tenet of science but has been challenging to achieve—we learned this the hard way when our old approaches proved inadequate to efficiently reproduce our own work. Here we describe how several free software tools have fundamentally upgraded our approach to collaborative research, making our entire workflow more transparent and streamlined. By describing specific tools and how we incrementally began using them for the Ocean Health Index project, we hope to encourage others in the scientific community to do the same—so we can all produce better science in less time.
Lowndes, Julia S. Stewart, et al. “Our path to better science in less time using open data science tools.” Nature ecology & evolution 1.6 (2017): 160.
Challenges & opportunities for libraries
The Strategic Value of Library Carpentry & The Carpentries to Research Libraries
For libraries, organizing Data, Software, and Library workshops and meet-ups have provided an excellent opportunity to connect with their community, understand their data and software needs, and grow their library services.
See:
https://librarycarpentry.org/blog/2018/08/library-carpentry-strategic-value/

Reasons why people come to Library Carpentry…
- People working in library- and information-related roles come to Library Carpentry hoping to:
- Cut through the jargon terms and phrases
- Learn how to apply data science concepts in library tasks
- Identify and use best practices in data structures
- Learn how to programmatically clean and transform data
- Work effectively with researchers, IT, and systems colleagues
- Automate repetitive, error prone tasks
38 mentions of The Carpentries in The Shifting to Data Savvy Report.
Demonstrated need from libraries
- Since 2013, roughly 120 Library Carpentry workshops have been held in 16 countries addressing software and data training needs from data cleaning in OpenRefine to versioning your work with Git.
- Update information above from https://librarycarpentry.org/upcoming_workshops/ and https://carpentries.org/upcoming_workshops/.
- Include information about your region/country/metro
Expanding Library Carpentry
The California Digital Library will advance the scope, adoption, and impact of the emergent “Library Carpentry” continuing education program… The training opportunities enabled by the project will provide librarians with the critical data and computational skills and tools they need to be effective digital stewards for their stakeholders and user communities.
See Institute of Museum and Library Services Grant RE-85-17-0121-17
On April 17, 2018, the California Digital Library welcomed Chris Erdmann, Library Carpentry Community and Development Director to help grow the Library Carpentry effort.
Growing Library Carpentry involves:
- Development and updates of core training modules optimized for the librarian community, based on Carpentries pedagogy
- Regionally-organized training opportunities for librarians, leading to an expanding cohort of certified instructors available to train fellow librarians in critical skills and tools, such as the command line, OpenRefine, Python, R, SQL, and research data management
- Community outreach to raise awareness of Library Carpentry and promote the development of a broad, engaged community of support to sustain the movement and to advance LC integration within the newly forming Carpentries organization
Involving community members has been key
- Developing Data Skills at Macquarie University Library: Drawing on Library Carpentry lessons, pedagogy and community . https://librarycarpentry.org/blog/2019/06/developing-data-skills/
- Building a Community for Digital Literacy at ZB MED: The Carpentries
and HackyHours A place where everyone can come together to share topics
and learn from each other
https://librarycarpentry.org/blog/2019/06/hackyhours-zbmed/ - New England Libraries Team Up to Become Carpentries Members:
Developing the New England Software Carpentry Library Consortium and a
Community of Practice
https://librarycarpentry.org/blog/2018/08/new-england-libraries-carpentries-consortium/ - University of Oregon Libraries and Oregon State University Libraries
Team Up to Teach First Library Carpentry Workshop in Oregon: UO and OSU
Library Carpentry report
https://librarycarpentry.org/blog/2018/08/oregon-libraries-report/ - Library of Congress, “Building Digital Content Management Capacity with Library Carpentry”, The Signal, November 9, 2018 https://blogs.loc.gov/thesignal/2018/11/library-carpentry/
Software, Data, and Library Carpentry at a glance
- The Carpentries: Building skills and community
- Non-profit teaching data science skills for more effective work and career development
- Training ‘in the gaps’ that is accessible, approachable, aligned and applicable (the practical skills you need in your work)
- Volunteer instructors, peer-led hands-on intensive workshops
- Open and collaborative lesson materials
- Creating and supporting community, local capacity for teaching and learning these skills and perspectives
Workshops
- 2-days, active learning
- Feedback to learners throughout the workshop
- Trained, certified instructors
- Friendly learning environment (Code of Conduct)
For images, see https://twitter.com/search?f=images&vertical=default&q=library%20carpentry%20workshop&src=typd
Workshops are 2-day, hands-on, interactive, friendly learning environment (Code of Conduct), teaching the foundational skills and perspectives for working with software and data
- Our workshops.
- Our learners.
- Our 2018 Annual Report (which includes data/highlights):
https://carpentries.org/files/reports/TheCarpentries2018AnnualReport.pdf
Focus of Data, Software, and Library Carpentry
- Data Carpentry workshops are domain-specific, and focus on teaching skills for working with data effectively and reproducibly.
- Software Carpentry workshops are domain-agnostic, and teach the Unix Shell, coding in R or Python, and version control using Git (i.e. Research software workflows).
- Library Carpentry workshops focus on teaching software and data skills for people working in library- and information-related roles. The workshops are domain-agnostic though datasets used will be familiar to library staff (i.e. Automating workflows, data cleaning, outreach to researchers/IT).
The Carpentries workshop goals
- Teach skills
- Get people started and introduce them to what’s possible
- Build confidence in using these skills
- Encourage people to continue learning
- Positive learning experience
Goals of the workshop, aren’t just to teach the skills, but to build self-efficacy and increase confidence and create a positive learning experience. We know we can’t teach everything in two days, but we want to teach the foundational skills and get people started and give them the confidence to continue learning. Many people have had demotivating experience when learning things like coding or computational skills, and we want to change that perspective.
Instructor training
Educational pedagogy is the focus of Instructor training program. The following steps are required to become a certified Instructor who can teach all Carpentries lessons!
- 2-days of online training in the pedagogy
- Suggest a change to a lesson on GitHub
- 1-hr online discussion on running/teaching workshops
- Online teaching demo
More information: http://carpentries.github.io/instructor-training/
Lesson maintenance
- We have an active community of lesson contributors and Maintainers that improve our 9 Library Carpentry lessons on a daily basi…
- What have the Library Carpentry Maintainers been working on? An
update on what the Library Carpentry Maintainers have been working on
since January 2019.
https://librarycarpentry.org/blog/2019/04/what-have-the-lc-maintainers-been-working-on/ - News from the Library Carpentry Maintainer Community and Curriculum
Advisory Committee: An update on Library Carpentry lesson
development
https://librarycarpentry.org/blog/2019/02/news-from-lc-maintainers/
Community opportunities
- Community of people excited about software and data skills and about sharing them with others
- Mentoring program and instructor onboarding
- Discussion groups and community calls
- Email lists
- Social media, chat channels
- Teaching at other institutions
- Lesson development and maintenance
Outcomes
Short and long term surveys show that people are learning the skills, putting them into practice and have more confidence in their ability to do computational work. See The Carpentries January 2018 long-term survey report
Outcomes
We also see researchers writing about the impact Carpentries training and approaches have had in their workflows:
Yenni, G. M., Christensen, E. M., Bledsoe, E. K., Supp, S. R., Diaz, R. M., White, E. P., & Ernest, S. M. (2019). Developing a modern data workflow for regularly updated data. PLoS biology, 17(1), e3000125. Chicago https://doi.org/10.1371/journal.pbio.3000125
Library Carpentry core objectives
Library Carpentry workshops teach people working in library- and information-related roles how to:
- Cut through the jargon terms and phrases of software development and data science and apply concepts from these fields in library tasks;
- Identify and use best practices in data structures;
- Learn how to programmatically transform and map data from one form to another;
- Work effectively with researchers, IT, and systems colleagues;
- Automate repetitive, error prone tasks.
How to get involved
How can I get started? Contribute to a lesson.
All of our lessons are CC-BY and hosted on GitHub at https://github.com/LibraryCarpentry. Anyone can contribute!
How can I get started? Host, help, teach.
Request a workshop:
https://amy.carpentries.org/forms/workshop/ (cost is 2500 USD to support instructor travel)Find a workshop in your area to attend/help with/observe:
https://carpentries.org (scroll down the page)Apply to be an Instructor:
https://carpentries.org/become-instructor/
Become a member
- How can I get started? Become a member.
- Find out more https://carpentries.org/membership/ and/or reach out to memberships@carpentries.org
Connect with The Carpentries
- The Carpentries Slack, email lists, Twitter, newsletter… https://carpentries.org/connect/
- Library Carpentry Slack, email list, Gitter, Twitter… https://librarycarpentry.org/contact/
Share information with your colleagues
What is your library/network doing to meet the data science needs of your community?
- Have you surveyed the needs of your community/library staff/members?
- What training programs have you taken/plan to take?
- If you have taken training programs, how have you incorporated what you have learned into your programs and services?
Thank you
- Your contact info
- Contact The Carpentries https://carpentries.org/connect/
Key Points
- Library Carpentry helps libraries…
- Cut through the jargon terms and phrases of software development and data science and apply concepts from these fields in library tasks.
- Identify and use best practices in data structures.
- Learn how to programmatically transform and map data from one form to another.
- Work effectively with researchers, IT, and systems colleagues.
- Automate repetitive, error prone tasks.
Content from Jargon Busting
Last updated on 2023-09-18 | Edit this page
Overview
Questions
- What terms, phrases, or ideas around code or software development have you come across and feel you should know better?
Objectives
- Explain terms, phrases, and concepts associated with software development in libraries.
- Compare knowledge of these terms, phrases, and concepts.
- Differentiate between these terms, phrases, and concepts.
Jargon Busting
This exercise is an opportunity to gain a firmer grasp on the concepts around data, code or software development in libraries.
- Pair with a neighbor and decide who will take notes (or depending on the amount of time available for the exercise, skip to forming groups of four to six).
- Talk for three minutes (your instructor will be timing you!) on any terms, phrases, or ideas around code or software development in libraries that you’ve come across and perhaps feel you should know better.
- Next, get into groups of four to six.
- Make a list of all the problematic terms, phrases, and ideas each pair came up with. Retain duplicates.
- Identify common words as a starting point - spend 10 minutes working together to try to explain what the terms, phrases, or ideas on your list mean. Note: use both each other and the internet as a resource.
- Identify the terms your groups were able to explain as well as those you are still struggling with.
- Each group then reports back on one issue resolved by their group and one issue not resolved by their group.
- The instructor will collate these on a whiteboard and facilitate a discussion about what we will cover today and where you can go for help on those things we won’t cover. Any jargon or terms that will not be covered specifically are good notes.
Busting Tips
Often, workshop attendees ask if there is a handout of common terms and definitions as there is not enough time to explain all the terms in a jargon busting exercise. Many of the terms are covered in our lessons such as Application Programming Interface (API), regular expressions, terminal, git… but with so much variation between our jargon busting sessions, it is difficult to create a common handout. You can start with resources such as TechTerms or the Data Thesaurus but you may also need to use the internet to explain terms. The Sideways Dictionary is another great place to get examples of jargon explained in plain English.
Keep in mind that our goal is not to explain all the terms we list out in the exercise, but instead to highlight how much jargon we use in our daily work and to come up with a shared understanding for a select number of jargon terms.
If you do have a helpful handout that you would like to share, please submit an issue/pull request to this lesson.
Key Points
- It helps to share what you know and don’t know about software development and data science jargon.
Content from A computational approach
Last updated on 2023-09-18 | Edit this page
Overview
Questions
- Why take an automated or computational approach?
Objectives
- Understand the main lessons of why you might automate your work.
Why take an automated or computational approach?
Otherwise known as the ‘why not do it manually?’ question. There are plenty of times when manual work is the easiest, fastest and most efficient approach. Here are two conditions that should make you consider using automation:
- You know how to automate the task.
- You think this is a task you will do over and over again.
Main lessons:
- Borrow, borrow, and borrow again. This is a mainstay of programming and a practice common to all skill levels, from professional programmers to people like us hacking around in libraries;
- The correct language to learn is the one that works in your local context. There truly isn’t a best language, just languages with different strengths and weaknesses, all of which incorporate the same fundamental principles;
- Consider the role of programming in professional development. Computational skills improve your efficiency and effectiveness. Stay alert to skills you want to learn, and be aware of what skills you can make sure your staff learn, as well.
- Knowing (even a little) code helps you evaluate projects that use code. Programming can seem alien. Knowing some code makes you better at judging the quality of software development or planning activities that include software development.
- Automate to make the time to do something else! Taking the time to gather together even the most simple programming skills can save time to do more interesting stuff! (even if often that more interesting stuff is learning more programming skills …)
Why automate?
Automation refers to a process or procedure that runs with little to no supervision or action. Libraries have been automating workflows for years and many of the Library Carpentry lessons can help people in libraries consider and implement automation approaches to further those efforts. You may often receive reports that you have to manually format or bibliographies where you have to clean metadata. If this sounds familiar, the tools and approaches introduced in Library Carpentry will help you automate and spend less time on these activities.
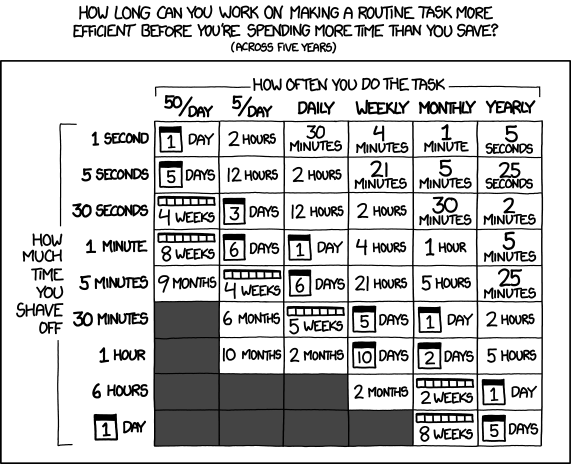
‘Is it worth the time?’ by Randall Munroe available at https://xkcd.com/1205/ under a Creative Commons Attribution-NonCommercial 2.5 License.
Is there something you would like to automate in your work?
Discuss in groups of four to six or altogether and note your discussion in the workshop collaborative document.
Key Points
- The main lessons of why you might automate or take a computational approach can help guide you as you consider whether to automate or not.
Content from Keyboard shortcuts
Last updated on 2023-09-18 | Edit this page
Overview
Questions
- What are keyboard shortcuts?
Objectives
- Learn commonly used keyboard shortcuts as a time saving tool.
Keyboard shortcuts are your friend
Though we will get more computational over the course of the programme, we can start our adventure into programming - as many of you will have already - with very simple things like keyboard shortcuts. We all have our favourites that are labour saving but also allow us to use this machine in the best possible way. You can do all the lessons in Library Carpentry without keyboard shortcuts, but note that they’ll likely come up a lot.
| Action | Windows | Mac | + Keystroke |
|---|---|---|---|
| Save | Ctrl | Command | + S |
| Copy | Ctrl | Command | + C |
| Cut | Ctrl | Command | + X |
| Paste | Ctrl | Command | + V |
| Switch Applications | Alt | Command | Tab |
Keyboard shortcuts are the first step towards automation. Sometimes you don’t have to write a programming script or use a program to automate.
What keyboard shortcut(s) do you find helpful?
Discuss in groups of four to six or altogether and note your discussion in the workshop collaborative document. For a list of common keyboard shortcuts, see Wikipedia’s Table of Keyboard Shortcuts.
Key Points
- Understanding keyboard shortcuts.
- Keyboard shortcuts are the first step towards automation.
Content from File naming & formatting
Last updated on 2023-09-18 | Edit this page
Overview
Questions
- What best practices and generic skills can be used to successfully use and create library related programs?
Objectives
- Identify best practices in naming and structuring files.
- Identify best practices in using software and data.
Names matter
We are all guilty of naming our files in such a way that sometimes we have a hard time finding them. For example, the following XKCD comic may be all too familiar.

‘Protip: Never look in someone else’s documents folder.’ by Randall Munroe available at https://xkcd.com/1459/ under a Creative Commons Attribution-NonCommercial 2.5 License.
There are a number of other bad file naming examples catalogued by Twenty Pixels such as the Overly Underscored or Signs of Frustration. Do any of these examples look familiar?
The File Organisation: Naming episode of Data Carpentry’s Reproducibility of Research lesson contains principles and examples that we can apply to finding and working with files that will save us time later. For example, ISO 8601, the preferred format for dates: YYYY-MM-DD. It introduces best practices such as using special case styles, ‘Kebab-case’ and ‘Snake_case’. Dryad has additional guidance on creating reusable data packages including folder and file structure.
Naming files sensible things is good for you and for your computers
Working with data is made easier by structuring your files in a consistent and predictable manner. Without structured information, our lives would be much poorer. As library and archive people, we know this. But let’s linger on this a little longer because for working with data it is especially important.
Examining URLs is a good way of thinking about why structuring data in a consistent and predictable manner might be useful in your work. Good URLs represent with clarity the content of the page they identify, either by containing semantic elements or by using a single data element found across a set or majority of pages.
A typical example of the former are the URLs used by news websites or blogging services. WordPress URLs follow the format:
ROOT/YYYY/MM/DD/words-of-title-separated-by-hyphens- https://cradledincaricature.com/2015/07/24/code-control-and-making-the-argument-in-the-humanities/
A similar style is used by news agencies such as a The Guardian newspaper:
ROOT/SUB_ROOT/YYYY/MMM/DD/words-describing-content-separated-by-hyphens- https://www.theguardian.com/uk-news/2014/feb/20/rebekah-brooks-rupert-murdoch-phone-hacking-trial
In data repositories, URLs structured by a single data element are often used. The National Library of Australia’s TROVE uses this format:
ROOT/record-type/REF- https://trove.nla.gov.au/work/6315568
The Old Bailey Online uses the format:
ROOT/browse.jsp?ref=REF- https://www.oldbaileyonline.org/browse.jsp?ref=OA16780417
What we learn from these examples is that a combination of semantic description and data elements make for consistent and predictable data structures that are readable both by humans and machines. Transferring this kind of pattern to your own files makes it easier to browse, to search, and to query using both the standard tools provided by operating systems and by the more advanced tools Library Carpentry will cover.
In practice, the structure of a good archive might look something like this:
- A base or root directory, perhaps called ‘work’.
- A series of sub-directories such as ‘events’, ‘data’, ’ projects’, etc.
- Within these directories are series of directories for each event, dataset or project. Introducing a naming convention here that includes a date element keeps the information organised without the need for subdirectories by, say, year or month.
All this should help you remember something you were working on when you come back to it later (call it real world preservation).
The crucial bit for our purposes, however, is the file naming
convention you choose. The name of a file is important to ensuring it
and its contents are easy to identify. Data.xslx doesn’t
fulfill this purpose. A title that describes the data does. And adding
dating convention to the file name, associating derived data with base
data through file names, and using directory structures to aid
comprehension strengthens those connections.
Plain text formats are your friend
Why? Because computers can process them!
If you want computers to be able to process your stuff, try to get in
the habit where possible of using platform-agnostic formats such as
.txt for notes and .csv (comma-separated
values) or .tsv (tab-separated values) for tabular data.
TSV and CSV files are both spreadsheet formats. These plain text formats
are preferable to the proprietary formats (e.g., Microsoft Word) because
they can be opened by many software packages and have a strong chance of
remaining viewable and editable in the future. Most standard office
suites include the option to save files in .txt,
.csv, and .tsv formats, meaning you can
continue to work with familiar software and save your files in the more
perennial formats. Compared to .doc or .xls,
these formats have the additional benefit of containing only
machine-readable elements.
When working with files for automation or computational purposes, it
is more important to focus on meaningful transmission of data as opposed
to fancy formatting. Whilst using bold, italics, and colouring to
signify headings or to make a visual connection between data elements is
common practice, these display-orientated annotations are not (easily)
machine-readable and hence can neither be queried and searched nor are
appropriate for large quantities of information. One rule of thumb is if
you can’t find it by
Ctrl+F/Command+F it isn’t
machine readable. Preferable are simple notation schemes such as using a
double-asterisk or three hashes to represent a data feature: for
example, we could use three question marks to indicate something that
needs follow up, chosen because ??? can easily be found
with a Ctrl+F/Command+F
search.
Use machine readable plain text notation for formatting
There are some simple notation schemes that are also plain text and
machine readable, but can be used to render simple formatting. One such
scheme is called Markdown, a lightweight markup language. A markup
language is a metadata language that uses notation to distinguish
between the content and the formatting of the content. Markdown files,
which use the file extension .md, are machine and human
readable. Markdown applications can be disparate, from simple to-do
lists, to extensive manual pages. For example, GitHub renders text via
Markdown. For instance, you can inspect the underlying
Markdown for this episode, File naming & formatting.
How can I format a Markdown file?
There are a number of ways we can do this, for instance hackmd.io or cryptpad.fr/code, we will use Dillinger.io referenced in the Markdown Guide. Go to Dillinger.io and change the headings to bold.
To bold text you can either use **bold text** or
__bold text__.
The Markdown Guide is a helpful resource for learning Markdown but you can also try:
For more advanced Markdown examples, the internet can be a helpful
resource. For instance, if you need to convert a .csv table
to a .md table you can find helpful resources such as Convert CSV to
Markdown.
The following resource provides further background on Markdown for
people in library- and information-related roles:
Ovadia, Steven. “Markdown
For Librarians And Academics.” Behavioral & Social Sciences
Librarian 33.2 (2014): 120-124.
Applications for writing, reading and outputting plain text files
We’ve already discussed why plain text formats are needed for working with data, and it’s also important to understand that you need different tools to work with these formats. Word processors like Microsoft Word, LibreOffice Writer, and Google Docs will explicitly not work for this purpose – those tools are meant to optimize how documents appear to humans, not to computers. They add many hidden characters and generally are unsuitable for working with plain text files. The category of tool you’ll want to use for data is called a text editor. Text editors save only the text that you type – there is no hidden formatting or metadata. What you see in a text editor is what a computer will see when it tries to process that data.
A free, cross-platform editor that works well for handling plain text files is Visual Studio Code. For Windows users, Notepad++ is recommended. Mac or Unix users may find Komodo Edit, Kate or Gedit useful. Combined with pandoc, a Markdown file can be exported to PDF, HTML, a formatted Word document, LaTeX or other formats, so it is a great way to create machine-readable, easily searchable documents that can be repurposed in many ways. This Programming Historian tutorial spells out what to do.
In Library Carpentry: The UNIX Shell lesson, we all see how the command line can be a powerful tool for working with text files.
Key Points
- Data structures should be consistent and predictable.
- Consider using semantic elements or data identifiers to data directories.
- Fit and adapt your data structure to your work.
- Apply naming conventions to directories and file names to identify them, to create associations between data elements, and to assist with the long term readability and comprehension of your data structures.
Content from One Up, One Down
Last updated on 2023-09-18 | Edit this page
Overview
Questions
- What did you like and what needs improvement about the lessons and workshop?
Objectives
- Learners reflect and share what they liked and what can be improved about the lessons and workshops.
- Instructors record the learner feedback and reflect on what can be improved about the lessons and workshops.
One-Up, One-Down
In addition to sticky notes used for feedback during the day, at the end of the day we can use a technique called “one up, one down”. The instructor asks the learners to alternately point to one thing they liked and one thing that can be improved about the day, without repeating anything that has already been said. This requirement allows participants to reflect further on the day and offer unique responses. The instructor writes down the feedback in the workshop collaborative document. The feedback is both helpful to the learners, to hear the perspectives of others in the workshop, and for instructors, to learn how the lessons and teaching approaches used can be improved.
Key Points
- It helps to reflect and share feedback about the lessons and workshop.
Content from Further reading
Last updated on 2023-09-18 | Edit this page
Overview
Questions
- Are there additional resources I can read to understand computational approaches in libraries?
Objectives
- Identify additional resources on computational approaches in libraries.
For further reading
Rosati, D. A. (2016). Librarians and Computer Programming: understanding the role of programming within the profession of librarianship. Dalhousie Journal of Interdisciplinary Management, 12(1).
de la Cruz, J., & Hogan, J. (2016). “Hello, World!”: Starting a Coding Group for Librarians. Public Services Quarterly, 12(3), 249-256.
Yelton, A. (2015). Coding for Librarians: Learning by Example.. American Library Association.
Burton, M., Lyon, L., Erdmann, C., & Tijerina, B. (2018). Shifting to data savvy: the future of data science in libraries.
Key Points
- Learn about computational approaches being applied in libraries.